Synopsis
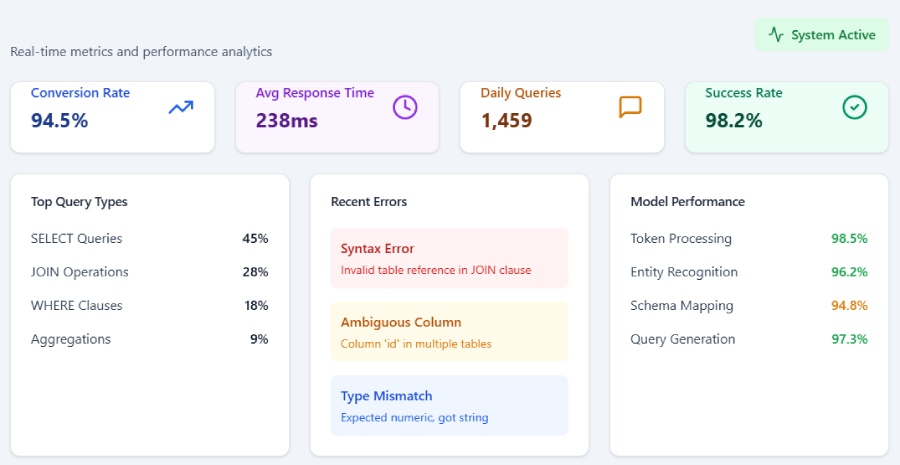
This case study explores the implementation of a Natural Language to SQL conversion system to streamline data analytics. The NL2 SQL system leverages NLP and machine learning to interpret and convert natural language queries into SQL, empowering non-technical users to extract insights seamlessly. Real-world examples demonstrate improved efficiency, accuracy, and user empowerment, reducing dependency on technical staff and enabling faster decision-making. This study showcases how NL2 SQL bridges the gap between non-technical users and complex data, facilitating data-driven decision-making.

Introduction
In recent years, the emergence of Data Transformer A.I. models have resulted in a significant boost in the development of A.I. technologies. Consequently, numerous Natural Language Processing (NLP) models have been developed and applied in various areas such as language translation, speech recognition, text summarization, sentiment analysis, and more. In our case, we aim to utilize these NLP models for the translation of natural language (NL) queries into SQL queries through the implementation of supervised learning techniques. To achieve this, we intend to design and create a custom dataset that will be used to train the models. The goal is for the model to effortlessly translate NL queries into SQL queries.
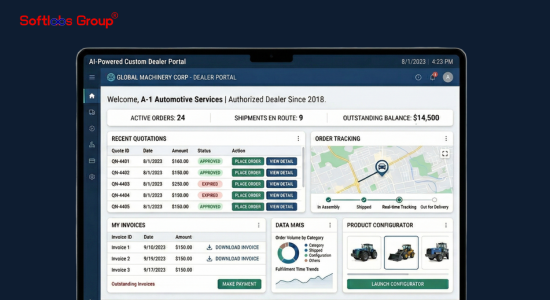
By employing a custom-trained A.I. for translation and seamlessly integrating it with the existing database, we eliminate the challenges faced by users when manually writing SQL queries. This not only saves time but also streamlines the process, making it more efficient and user-friendly.
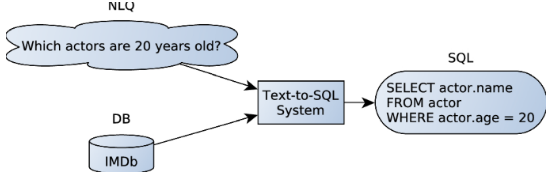
NL2SQL Model:
There are many NLP models which have been custom fitted for translation of NL2SQL. And each differing in the results and efficiency based on the type of database it has been used for. For our case study, we picked Google’s Bert t5 model which is trained on a custom SQL query dataset.
The model functions well with the Dataset of 56,000 unique queries and translates NL2SQL within the parameters provided in the Dataset.
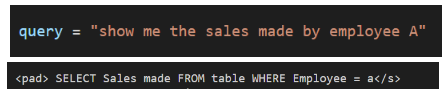
The following is an example of the queries within the dataset:
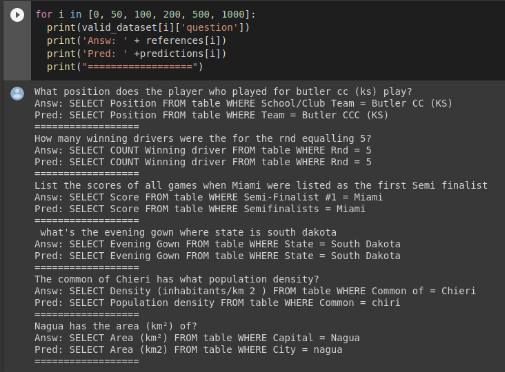
We would also apply Data Augmentation using PPDB (paraphrasing database). This would help us with different way a certain NL query can be paraphrased and thus improve and increase our model’s accuracy.
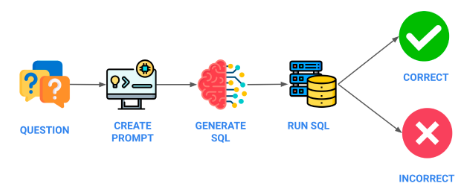
Following is the complete process that needs to be undertaken to create a custom trained model:
Analysis of data features:
- Analysis of the SQL database and identifying the key features and structure of the model and creating a skeleton of the interlinked connection of the database.
Preprocessing the Data
- Creation of all possible SQL queries from the key features and linked database.
NL Data Augmentation:
- Creating NL queries for the SQL queries. then using paraphrasing augmented data.
Data Labelling:
- Labelling the NL queries with the SQL queries.
Data cleaning:
- Analysis of the dataset created and rectifying it.
Model Selection and Analysis:
- Selection of a model which is best suited for our custom dataset.
Model Training and testing:
- Training the model and testing its response to our queries.
- Model Evaluation and Retraining.
- Changes to dataset if needed.