Introduction
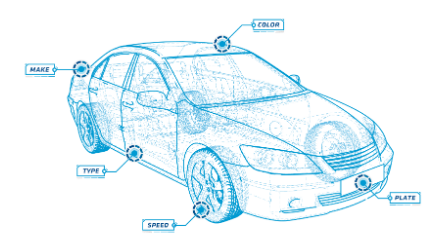
The CarTrust project focuses on developing a sophisticated object detection model integrated into a mobile application to accurately identify vehicle details such as make, model, manufacturing year, and variant in real-time. The objective is to achieve maximum accuracy in recognizing these vehicle specifics, enhancing user experience and reliability.
Problem Statement
The primary challenge was to create a robust object detection model that could seamlessly integrate into a mobile application. This model needed to identify essential details about vehicles, including their make, model, manufacturing year, and variant (trim), using the device’s camera to provide real-time insights.
Current Research
While working on the given problem statement, we decided to use YOLO (You Only Look Once) object detection models. These models are known for providing accurate results and require relatively less computation time for predictions, making them suitable for real-time applications.
We chose the Stanford Cars Dataset for our testing, which includes over 190 different car classes categorized by their make, model, and manufacturing year. We used a total of 16,185 images from this dataset for training and testing our model.


The initial results from the training sessions were satisfying. The model successfully differentiated between various cars, accurately identifying their make, model, and manufacturing year from a single perspective. However, our team speculated that to improve accuracy further, we could use multiple images of each car taken from different viewpoints like front, back, and side. Combining the results from these perspectives could enhance the overall prediction accuracy.

Moving forward, we expect this multi-perspective approach to strengthen the model’s understanding, providing a more detailed insight into the visual characteristics of each vehicle. This improvement is aimed not only at increasing accuracy but also at making the model more capable of handling variations in viewpoints, contributing to a reliable and versatile object detection solution.
Current evaluation criteria from the app:
Mileage (km):
- Evaluation based on the total distance the car has travelled.
- Higher mileage may influence a decrease in price due to potential wear and tear.
Accidents History:
- Assessment of the car’s involvement in any accidents.
- A clean history may positively impact the price, while a history of accidents may lead to a reduction.
Car Colour:
- Subjective evaluation based on the colour of the car.
- Some colours may be more popular and may affect perceived value.
Purpose of Use:
- Consideration of whether the car was primarily used for personal or commercial purposes.
- Commercial use may impact depreciation and influence pricing.
Origin:
- Evaluation based on the region or country of origin of the car.
- Some origins may be associated with higher quality or reliability, affecting pricing.
Maintenance History:
- Assessment of the car’s maintenance records and service history.
- Regular maintenance may positively influence the price.
Inspected by CarTrust:
- Whether the car has undergone inspection by CarTrust.
- A positive inspection may contribute to a higher perceived value.
Warranty Provider:
- Existence of a warranty provided by a reputable provider.
- Warranties can add value and may positively impact pricing.
Modifications to the Car:
- Consideration of any aftermarket modifications made to the car.
- Modifications may affect the price, either positively or negatively, based on their nature.
Proposed model architectures
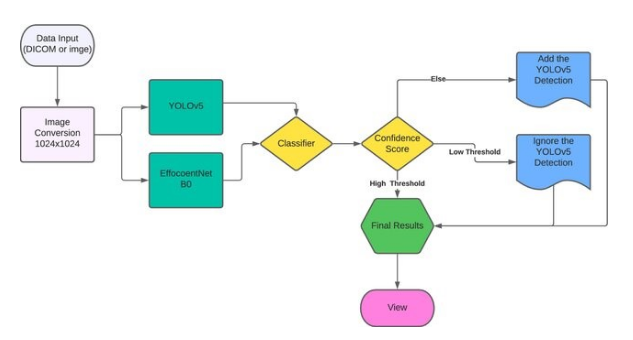
A dual model architecture combining YOLOv7 and Efficient Net can leverage the strengths of both models for more accurate object detection and classification tasks. Here’s a summarized overview:
Dual Model Architecture: YOLOv7 + Efficient Net
Object Detection with YOLOv7:
- YOLOv7 is utilized for efficient and real-time object detection.
- YOLOv7 divides the input image into a grid and predicts bounding boxes, abjectness scores, and class probabilities for each grid cell.
- The strength of YOLOv7 lies in its ability to provide accurate bounding box predictions and handle multiple objects within an image simultaneously.
Feature Extraction with Efficient Net:
- Efficient Net is employed as a feature extractor to capture high-level features from the input image.
- Efficient Net is known for its ability to balance model size and accuracy, making it efficient for feature extraction in various computer vision tasks.
Integration of YOLOv7 and Efficient Net:
- Features extracted by Efficient Net are combined with the output from YOLOv7’s detection head.
- The combined features are used to enhance the accuracy and robustness of object detection predictions.
Training Strategy:
- The combined model is trained in a supervised manner using a dataset that includes both annotated bounding boxes and class labels.
- YOLOv7’s loss functions for bounding box prediction, abjectness, and class probabilities are used alongside Efficient Net’s classification loss.
Inference and Prediction:
- During inference, the dual model architecture takes advantage of YOLOv7’s real-time object detection capabilities for precise localization of objects.
- Efficient Net’s features contribute to better classifying the detected objects, leading to improved accuracy in object recognition.
Benefits of Dual Model Architecture:
- YOLOv7 provides efficient and fast object detection, while Efficient Net enhances feature extraction for better classification accuracy.
- The combination of these models aims to achieve a more comprehensive understanding of the input images, leading to improved overall prediction performance.
We can swap different YOLO models and CNN models based on the required performance and accuracy index.
Model Output
Following are the examples of the classes for the model and the outputs generated:
- Porsche_911_Porsche_2019_Red
- Toyota_Camry_Toyota_2020_Blue
- Ford_Mustang_Ford_2018_Black
- Honda_Civic_Honda_2017_Silver
- BMW_X5_BMW_2022_White
- Chevrolet_Malibu_Chevrolet_2016_Green
- Mercedes-Benz_S-Class_Mercedes-Benz_2021_Grey
- Volkswagen_Golf_Volkswagen_2015_Yellow
- Nissan_Altima_Nissan_2014_Orange
- Tesla_Model_S_Tesla_2023_Purple
In these examples:
- Car Model represents the specific model of the car (e.g., Porsche 911, Toyota Camry).
- Car Make represents the make or brand of the car (e.g., Porsche, Toyota).
- Car Year represents the manufacturing year of the car (e.g., 2019, 2020).
- Car Colour represents the colour of the car (e.g., Red, Blue).
These labels provide detailed information about each car in the dataset, making it easy to identify the car’s model, make, year, and colour from the label itself.
Proposed model Training and Dataset Collection
Creating a dual model architecture using YOLOv7 (You Only Look Once version 7) and Efficient Net B0 involves combining object detection and image classification models. YOLOv7 is known for its real-time object detection capabilities, while Efficient Net is a family of efficient convolutional neural networks designed for image classification.
Here is a proposed approach for training and dataset collection:
1) Dataset Collection:
Object Detection (YOLOv7):
- Collect a diverse dataset that represents the types of objects you want to detect.
- Annotate the dataset with bounding boxes around the objects of interest. Tools like LabelImg or VGG Image Annotator (VIA) can be helpful for this task.
- Ensure a balanced distribution of object classes to avoid bias in the training process.
Image Classification (Efficient Net B0):
- Collect a separate dataset for image classification. This dataset should include a variety of images with different scenes and objects.
- Annotate the dataset with corresponding class labels for each image.
2) Data Preprocessing:
Object Detection (YOLOv7):
- Resize images to a size compatible with YOLOv7 input requirements.
- Convert annotations to YOLO format (centre coordinates, width, height).
- Normalize pixel values of images.
Image Classification (Efficient Net B0):
- Resize images to the input size required by Efficient Net B0.
- Normalize pixel values.
Dual Model Integration:
- Once both models are trained individually, integrate them into a dual model architecture.
- The output of the YOLOv7 model can be used to detect objects in an image, and the regions containing objects can be passed through the Efficient Net B0 model for further classification.
Evaluation and Fine-tuning:
- Evaluate the performance of the dual model on a validation dataset.
- Fine-tune the models if needed, considering metrics such as precision, recall, and accuracy.
Model Deployment on Android and iOS:
Android:
- Integrate the TensorFlow Lite model into your Android app.
- Use the TensorFlow Lite Android Support Library for easy integration.
- Follow TensorFlow Lite Android guide for detailed steps: TensorFlow Lite Android.
iOS:
- Integrate the TensorFlow Lite model into your iOS app.
- Use the TensorFlow Lite iOS Support Library for smooth integration.
- Follow TensorFlow Lite iOS guide for detailed steps: TensorFlow Lite iOS.
App Design Integration:
- Ensure that your app’s design accommodates the object detection results appropriately.
- Utilize UI components to display bounding boxes, labels, and other relevant information.
- Optimize the user experience for seamless interaction with the object detection features.
Testing and Optimization:
- Test your integrated models on both Android and iOS devices.
- Optimize the models for inference speed and memory usage as needed.
- Address any performance bottlenecks or issues that arise during testing.
Continuous Improvement:
- Keep an eye on new releases and updates for both YOLOv7 and Efficient Net.
- Consider implementing any new techniques or improvements to stay at the forefront of object detection and classification.