Executive Summary: Why Tariff Classification Has Become a Strategic Risk
Your team receives a shipment notification for 4,000 new SKUs from three suppliers in different countries. Each one needs a valid 10-digit HTS code before customs filing – correctly assigned, legally defensible, and recorded with supporting rationale in case CBP comes knocking. The manual process takes days, costs hundreds of dollars per hour in broker fees, and still produces an error rate that exposes your organisation to penalties running into the millions. That is the daily operational reality for trade compliance directors, customs brokers, and supply chain teams managing high-volume cross-border imports today.
An AI HTS code classification solution addresses this problem directly. By combining large language model reasoning with authoritative tariff content, legal-rule logic, and human oversight at critical decision points, these systems accelerate the classification workflow without removing the accountability structures that compliance demands. The result is not AI replacing customs expertise – it is AI doing the heavy lifting so licensed professionals spend their time where judgment genuinely matters.
This page explains how AI-driven HTS classification works, what it realistically delivers, where it has limits, and what a sound implementation looks like for organisations operating in today’s increasingly complex trade environment.
Why Does Tariff Misclassification Keep Getting Worse Without AI?
Context: The Operational Reality of Global Trade Compliance
Trade compliance teams operate inside a system that compounds pressure from multiple directions simultaneously. The U.S. Harmonized Tariff Schedule contains over 21,000 specific 10-digit codes across 99 chapters – and a single digit difference between two adjacent codes can swing duty rates from zero to 25 percent or more. Meanwhile, policy changes arrive with little warning: Section 301 tariff layers, de minimis rule revocations, and country-specific schedule amendments all require teams to reclassify existing catalog items at speed. The volume of affected shipments is growing, not shrinking.
In practice, organisations deploying manual classification workflows typically encounter a structural mismatch: the expertise required to classify accurately is expensive, the volume demanding classification is enormous, and the regulatory environment changes fast enough to invalidate prior decisions without notice. Licensed customs brokers sit one of the most difficult professional licensing exams in the United States, with pass rates that have historically ranged from single digits to around 30 percent per sitting – keeping the certified talent pool tight relative to demand. Professional classification services from major firms can run to $100 per item, and for companies managing catalogs of thousands of SKUs, that cost structure is simply unsustainable.
Key Pain Points This AI Solution Addresses
- Wrong tariff codes causing penalties and audits: misclassification accounts for 42% of all CBP customs penalties – the single most common compliance failure category. Under 19 USC §1592, penalties for negligent misclassification can reach the full domestic value of the merchandise, and gross negligence multiplies that exposure further.
- Manual HS classification too slow for high import volumes: Teams handling thousands of shipments per month cannot manually research and document every classification decision. The bottleneck forces organisations to either pay for expensive broker time on routine items, or accept unreviewed classifications that increase audit exposure.
- Inconsistent product classification across shipments: Without a centralised classification record, the same product description often receives different codes across different filings, different brokers, or different country contexts. CBP audits specifically look for these patterns.
- Tariff complexity from trade policy changes overwhelming teams: Rapid policy changes – Section 301 tariff updates, de minimis revocations, CBAM implementation – require teams to revalidate existing classifications at speed, often without additional headcount.
- Product descriptions too vague for accurate classification: Supplier-provided descriptions rarely match the specificity that HS classification actually requires. Material composition, intended use, functional distinction, and part-versus-finished-good status all drive classification outcomes – and suppliers rarely document these systematically.
- High cost of customs broker classification services: Professional classification review at scale is economically impractical for catalog-heavy importers. The cost per classification from major professional services firms makes manual approaches unscalable past a few hundred annual SKUs.
- Customs audit risk from classification inconsistencies: CBP examination rates for companies with violation histories average 15 to 20 percent, compared to 2 to 3 percent for compliant importers – creating a compounding cost that persists for years after the original error.
Why Traditional Approaches Fall Short
Manual classification by customs brokers or in-house analysts remains the gold standard for accuracy on complex individual items – but it does not scale. Accuracy degrades under volume pressure, and even experienced professionals encounter significant uncertainty on complex items where two headings appear plausible or where classification turns on legal notes that require careful sequential interpretation. The economics of broker fees make manual approaches prohibitive for large catalogs regardless of the accuracy question.
Legacy rule-based software from earlier generations attempts to automate classification using keyword matching and lookup tables. However, keyword matching fails on the very cases that matter most: items where classification turns on legal notes, essential character determinations, or competing headings that require stepwise GRI reasoning rather than simple text similarity. A system that returns plausible-looking codes without applying the underlying legal logic creates false confidence – the most dangerous outcome in a compliance context.
General-purpose AI tools like standard LLMs are not a reliable solution either. Practitioner experience confirms that plain generative AI tends to surface the most statistically common code for a product description rather than reasoning through the General Rules of Interpretation systematically. The result is confident-sounding outputs that can fail CBP format validation or misapply legal notes in ways that only become visible at audit. The AI HTS code classification solution architecture this page describes is specifically engineered to close that gap.
What Is an AI HTS Code Classification Solution – and How Is It Different?
An AI HTS code classification solution is a purpose-built system that combines structured product data intake, authoritative tariff content retrieval, legal-rule reasoning, and human oversight to produce accurate, explainable, audit-ready classification recommendations. The distinction from generic AI tools is architectural: rather than asking a language model to guess a code from a product description, a well-designed AI HTS classification solution forces the system to collect the product facts that actually drive classification, retrieve the relevant legal content, apply the rules in sequence, and explain every step of its reasoning before a human reviewer approves the result.
The practical effect is a copilot model rather than an autopilot model. AI handles the research, attribute extraction, candidate generation, and draft rationale preparation. Licensed professionals handle the final sign-off, edge case judgment, and legal accountability. That division reflects both the current state of the technology and the legal reality: the importer of record remains fully responsible for classification accuracy regardless of what any software system suggests.
Vision and Objectives
- Reduce classification time per SKU from hours of manual research to minutes of guided review, enabling teams to process large catalogs without proportional increases in broker or analyst headcount.
- Improve classification accuracy by grounding every recommendation in authoritative sources – tariff schedules, chapter and section notes, WCO explanatory content, and historical rulings – rather than relying on keyword matching or LLM pattern recall alone.
- Produce defensible classification records with full source attribution, reasoning trails, and reviewer sign-off documentation that satisfy CBP reasonable-care requirements and survive audit scrutiny.
- Build institutional product memory so approved classifications for known SKUs become reusable assets, reducing rework when the same product appears under a new supplier name or description variant.
- Flag classification risk before filing by identifying low-confidence cases, competing heading scenarios, and policy-change impacts early in the workflow rather than after CBP examination.
- Integrate into existing operations through API connections to ERP systems, customs platforms, and freight management tools so classification happens inside the workflows teams already use, not in a separate silo.
Who Uses AI-Driven HTS Classification – and What Does It Change?
Scenario 1: High-Volume Ecommerce Importer – Managing Thousands of New SKUs Each Season
Your product team just finalised the spring catalog: 3,200 new SKUs sourced from six Asian suppliers, all needing valid HTS codes before the first shipment. Your one-person trade compliance function already handles day-to-day filings, amendments, and broker coordination. There is no realistic path to manually classifying 3,200 items before the shipping window closes.
Manual bulk classification at this volume would require weeks of broker time at costs that would materially affect product margin. Supplier-provided codes are often recycled from prior seasons without verification and frequently fail CBP format checks or carry the wrong duty rate under updated Section 301 layers.
An AI HTS classification solution ingests the product catalog data in bulk, extracts attributes from supplier descriptions, flags the items missing material or composition data, and generates classification recommendations with confidence scores. The compliance lead reviews only the flagged low-confidence items and approves the high-confidence batch classifications. The concrete outcome: a 3,200-SKU catalog reaches defensible classification status in days rather than weeks, with full documentation ready for broker handoff.
Scenario 2: Trade Compliance Director at a Mid-Size Manufacturer – Navigating Tariff Policy Changes
A trade policy update arrives on a Friday afternoon: additional Section 301 tariff layers take effect on Chinese-origin goods in your product categories within 30 days. You need to identify which of your 900 active SKUs are affected, revalidate their classifications, and update your ERP duty rates before the next shipment cycle.
Running that analysis manually means pulling each classification, cross-referencing the policy update language, and redocumenting any affected items – a process that can take a compliance team weeks when managing hundreds of product lines simultaneously.
An AI-driven HTS classification system with versioned tariff data can run an impact analysis across the entire active product library, identify the specific SKUs where classification is affected by the new tariff layer, and queue those items for priority re-review. The compliance director focuses on the 80 items flagged as potentially affected rather than auditing all 900. The outcome: the 30-day window becomes manageable, and the ERP update happens before the first affected shipment crosses the border.
Scenario 3: Licensed Customs Broker – Scaling Classification Volume Without Scaling Headcount
You run a mid-size customs brokerage handling filings for 40 importer clients. Classification quality is your professional reputation – a bad ruling on a high-value client shipment exposes both your client and your license. But new client onboarding keeps adding SKU volume that your current analyst team cannot absorb without adding headcount that your current fee structure does not support.
The economic pressure pushes brokerages toward either turning away growth or accepting marginal classification quality on lower-risk items. Neither outcome is acceptable long-term.
An AI tariff classification platform for importers and exporters allows brokerage analysts to handle significantly higher SKU volume by using AI to complete the research and draft-rationale phases while analysts focus on review and sign-off. The system reuses prior approved classifications for known products and escalates novel or ambiguous items to senior reviewers. The result: classification capacity increases without a proportional headcount increase, and every decision retains the audit trail that professional liability requires.
Ready to explore what this solution looks like for your organisation?
Talk to Our AI TeamHow Does an AI HTS Code Classification Solution Actually Work?
A well-architected AI HTS classification solution separates the classification problem into discrete, controllable stages rather than asking a single model to jump directly from a product description to a 10-digit code. Each stage addresses a specific failure mode that makes direct-to-code approaches unreliable. The following describes how data moves through such a system from intake to approved output.
Solution Architecture: How the System Is Structured End to End
The diagram below maps the full pipeline – from raw product data intake through to the approved, audit-logged record – showing where AI operates autonomously, where human review applies, and how the learning loop feeds approved institutional decisions back into the retrieval layer.
Data Acquisition: Product Data Sources and Inputs
The system accepts product data from multiple sources: CSV and Excel catalog exports from ERP or PIM systems, PDF product specifications and technical data sheets, supplier invoices and packing lists, manual entry for individual SKU queries, and image inputs for visual product identification where available. Because real-world product data is rarely clean or complete, the ingestion layer is designed to handle partial, inconsistent, and multi-format inputs rather than requiring structured data as a prerequisite.
The classification knowledge layer – the authoritative content the system reasons over – draws from the current HTS schedule and legal notes, WCO Explanatory Notes, the CBP CROSS database of searchable customs rulings, historical binding rulings, and the organisation’s own approved product classification library from prior filings. This combination of regulatory content and institutional precedent is what separates a knowledge-grounded system from a general-purpose language model operating on training data alone.
The AI Processing Pipeline
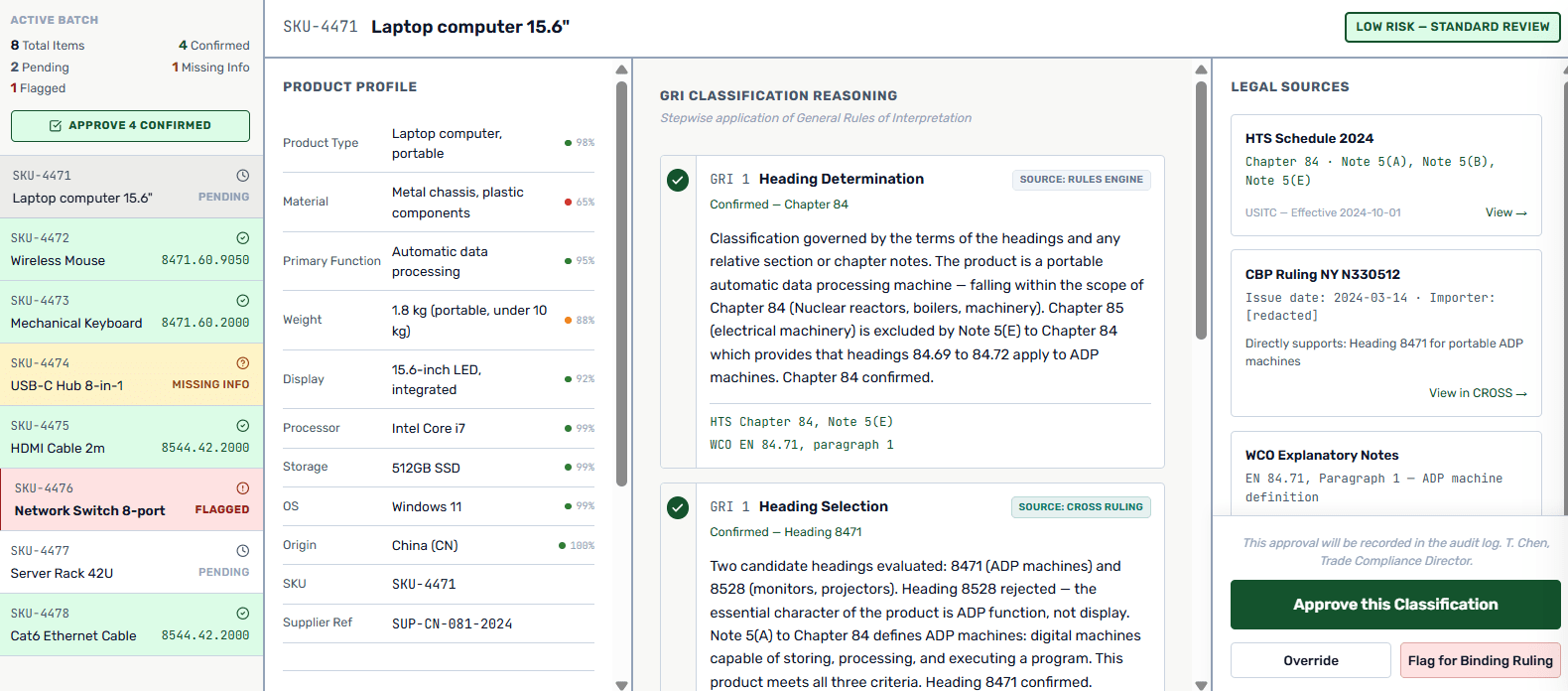
- Attribute Extraction and Product Normalisation: First, the system parses each product input and extracts the structured attributes that actually drive classification outcomes – material composition, primary function, intended use, physical form, part-versus-finished-good status, and set or kit configuration. Raw descriptions like “widget assembly” are insufficient for classification; this stage converts messy source language into a structured product profile against which legal rules can be applied. OCROptical Character Recognition – technology that converts scanned documents or images into machine-readable text for further processing and document parsing handle PDF and image inputs automatically.
- Missing-Information Detection and Targeted Clarification: Next, the system evaluates the extracted product profile against the classification requirements for candidate heading ranges. Where critical attributes are missing – for example, material composition percentage needed to distinguish competing headings – the system generates targeted clarification questions for the user rather than proceeding on incomplete data. This stage prevents the most common failure mode in automated classification: confident recommendations based on insufficient product facts.
- Legal Content Retrieval: Once the product profile is sufficiently complete, the system retrieves the relevant legal content from the knowledge layer. This includes candidate heading descriptions from the HTS, the applicable section and chapter notes, relevant WCO Explanatory Notes, and prior CROSS rulings on similar products. Retrieval-Augmented Generation (RAG)An AI architecture that grounds language model outputs in retrieved documents from an authoritative knowledge base rather than relying on model training data alone ensures the reasoning step works from verified, versioned regulatory content rather than LLM pattern recall.
- Stepwise Heading Analysis and GRI Application: The system then applies the General Rules of Interpretation (GRI)The six legally binding rules under the Harmonised System that govern how all tariff classification decisions must be made – applied in sequence, starting with specific heading text in sequence. Starting from candidate headings identified by the retrieval step, it tests each heading against the legal notes, applies exclusion rules, evaluates competing subheadings at the same level, and documents the analysis at each stage. This replicates the stepwise decision process a trained customs analyst would follow, rather than selecting the most statistically similar code from training data.
- Candidate Code Generation with Confidence Scoring: The system then produces the top candidate 10-digit classifications – typically two to three options – each accompanied by the supporting reasoning, source citations, and a confidence score. The confidence score reflects how well-supported the recommendation is by the retrieved legal content and the completeness of the product profile, not simply the model’s internal probability estimate. Low-confidence scores automatically route items to the human review queue; high-confidence scores on items matching prior approved classifications can proceed to expedited review.
- Memo Generation and Output Packaging: Finally, the system assembles the classification recommendation into a structured decision memo that includes the recommended code, the top alternative considered and why it was rejected, the specific legal notes and rulings cited, the product attributes relied upon, and the confidence and risk level. This memo is the artefact that satisfies CBP reasonable-care documentation requirements and provides the evidence base a reviewer needs to approve or override the recommendation efficiently.
What Core Features Does a Production-Ready System Include?
The features below reflect what practitioners and compliance teams consistently identify as the gaps that most current classification tools leave open. The front-end experience should feel like a guided case intake form – not a technical AI console. The operational discipline lives in the backend.
- Guided SKU intake from CSV, ERP exports, PIM catalogs, PDFs, supplier invoices, and manual entry – because real-world data rarely arrives in a clean, structured format.
- Attribute extraction into structured fields – material composition, primary function, intended use, physical form, part or accessory status, and kit or set configuration – converting messy source language into the structured facts classification actually requires.
- Targeted clarification questions before classification proceeds, triggered when critical attributes are missing rather than allowing the system to guess from incomplete data.
- Top 3 candidate codes per classification with the alternatives considered and the specific reason each was rejected – never a single blind answer that hides uncertainty.
- Justification memo with cited sources – the specific HTS heading text, chapter or section notes, WCO Explanatory Notes references, and CROSS rulings cited as the basis for each recommendation.
- Confidence score and risk flag per item, with automatic routing: high-confidence items with prior approved matches proceed to expedited review; low-confidence, novel, or policy-impacted items route to the full reviewer queue with context.
- Human approval queue with role-based routing – analysts, senior reviewers, and licensed customs professionals assigned to the appropriate item tier based on complexity and risk level.
- Product library with similarity matching – approved classifications for known SKUs become reusable institutional precedent. The next similar product starts from the organisation’s own approved history, not from scratch.
- Bulk classification for catalogs – batch processing for new product introductions, seasonal catalog additions, and supplier migrations at any volume.
- Tariff schedule versioning and change-impact alerts – when official schedule updates are applied, the system flags existing approved classifications in affected chapters for revalidation rather than silently continuing on a stale schedule.
- Full audit trail recording who approved each classification, when, on which tariff data version, with which evidence – the documentation package that satisfies CBP reasonable-care requirements.
- API and dashboard access for operations and compliance teams, with ERP integration for duty-rate updates and customs platform connectivity for filing workflows.
Human-in-the-Loop: Where Human Judgment Still Matters
A common pattern across real implementations of this solution is that the most valuable human oversight moments are not on routine items – they are on the specific cases where two headings appear legally plausible and the outcome turns on an “essential character” determination or a novel product configuration the system has not encountered in prior approved history. Identifying those cases accurately and routing only them to human review is what makes the copilot model economically viable.
- Final approval on all classifications: Every classification recommendation requires explicit human sign-off before CBP filing. The system generates recommendations; licensed customs professionals or designated compliance reviewers make the binding decision. This is non-negotiable under current legal frameworks – the importer of record bears full responsibility regardless of what any AI system suggests.
- Mandatory review on low-confidence and flagged items: Items below the confidence threshold, items with competing headings at the same GRI level, novel products with no prior approved internal match, and items in categories subject to recent policy changes all route directly to the reviewer queue with full context.
- Override and feedback capture: Reviewers can override any system recommendation. All overrides trigger a feedback loop that updates the product library and, over time, improves system performance on similar future items. The system learns from institutional decisions, not from retraining on external data.
- Periodic audit and calibration: Compliance leads should periodically sample approved classifications across the confidence spectrum to verify that high-confidence batch approvals remain accurate as tariff schedules and product ranges evolve.
- Binding ruling escalation: For high-value, high-risk, or genuinely ambiguous classifications where no clear legal answer exists, the system flags the case for a formal CBP binding ruling request rather than defaulting to the most probable code.
Output and Interaction: What Users Actually See
For day-to-day users – trade compliance analysts, broker staff, or operations teams – the experience resembles a guided case intake and review workflow rather than a technical AI tool. The user sees a structured product form with pre-populated fields from the intake, a small set of clarifying questions where attributes are missing, and then a review screen showing the top recommendation, the supporting rationale, and the alternative considered.
Approved classifications flow into an exportable classification record for broker handoff, ERP update, or ABI filing preparation. Bulk catalog outputs produce structured reports with per-SKU classifications, confidence levels, and reviewer notes. Integration-enabled deployments push approved classifications directly to connected ERP, customs platform, or freight management systems via API. For operations teams, the system also surfaces a tariff change alert dashboard – flagging existing approved classifications that may require revalidation when schedule updates or new policy layers are published.
What Technologies Power an AI HTS Classification Solution?

- Large Language Models (LLMs)Advanced AI models trained on large text corpora that can perform complex language understanding, reasoning, and generation tasks when appropriately constrained: Purpose-fine-tuned or carefully prompted LLMs handle the explanation, reasoning articulation, and clarifying question generation steps of the pipeline. Fine-tuned models trained on customs ruling data outperform general-purpose models significantly on tariff classification tasks – research published on the ATLAS benchmark found that a fine-tuned model on CROSS rulings data outperformed GPT-5-Thinking by 15 percentage points at the 10-digit classification level. However, LLMs are always constrained by authoritative retrieved content in a sound system – never operating on free-form generation alone.
- Retrieval-Augmented Generation (RAG) with Structured Knowledge Bases: RAG grounds every LLM output in retrieved content from versioned tariff schedules, legal notes, and ruling databases. This prevents hallucination, ensures the reasoning reflects current schedule versions, and produces citations that auditors and reviewers can verify directly. The knowledge base requires ongoing maintenance as tariff schedules are revised.
- Natural Language Processing (NLP)AI techniques for extracting structured information from unstructured text – used here to parse product descriptions and extract classification-relevant attributes like material, function, and composition: NLP pipelines convert supplier product descriptions, invoice text, and specification document language into the structured attribute fields the classification reasoning layer requires. This normalisation step is critical – without it, messy real-world product language defeats downstream accuracy.
- Vector Search and Semantic Retrieval: Vector embedding models enable similarity-based retrieval of prior CROSS rulings, internal approved classifications, and explanatory notes that are conceptually relevant to a product even when exact keyword matches are absent. This is particularly valuable for novel product descriptions with no direct precedent in the ruling database.
- Rules Engine for GRI and Legal Note Application: A deterministic rules engine applies the hard structural constraints of the Harmonised System – GRI sequencing, exclusion rules, essential character tests – in a controlled, auditable way separate from the probabilistic LLM layer. This separation means the legal logic cannot be “argued away” by the language model and produces consistent, verifiable rule-application records.
- Confidence Scoring and Risk Classification: Calibrated confidence scoring – distinct from raw LLM probability estimates – evaluates the strength of the legal-content support for a recommendation, the completeness of the product profile, and the proximity to prior approved decisions. This score drives the routing logic that determines which items need human review and which can proceed to expedited approval.
- Workflow Orchestration and Audit Logging: A workflow engine manages the reviewer queue, role-based approval routing, version history for both product profiles and tariff data, and the feedback loop from reviewer decisions back into the product library. Comprehensive audit logging records every decision, every override, and every data version used – the documentation foundation for CBP reasonable-care compliance.
What Does the Recommended Technology Stack Look Like?
The most practical build separates AI capabilities from deterministic control layers. AI handles extraction, explanation, and candidate generation. Structured systems handle memory, rules, approvals, and traceability. The rule the architecture must follow: the LLM layer cannot freely improvise legal answers – it works from retrieved, versioned content with constrained outputs.
- Frontend and Interface: React or Next.js with TypeScript for the web application and reviewer dashboard. The user experience should feel like a guided case intake form plus a review screen – not a technical AI tool. Tailwind CSS or Material UI for component styling.
- Backend APIs and Orchestration: Python FastAPI or Node.js with TypeScript for API services. Temporal, n8n, or a queue-based worker setup for multi-step workflow orchestration including review queues, approval routing, and tariff-change impact analysis runs. PostgreSQL for case records, approvals, classification history, product profiles, and user management.
- Document Processing: Azure Document Intelligence, Google Document AI, or open-source OCR with custom parsers for PDFs, images, and supplier documents. Schema-based attribute extraction converts parsed text into the structured fields (material, composition percent, function, part or finished-good status) the classification engine requires.
- AI and Reasoning Layer: A strong reasoning LLM for classification memo generation, clarification question formulation, and rationale explanation – configured with prompt templates and JSON-constrained outputs so it cannot improvise freely on legal answers. The model operates only over retrieved tariff content, not on training data recall. S3-compatible object storage for document inputs and classification artefacts.
- Search and Retrieval: OpenSearch or Elasticsearch for keyword-based retrieval of HTS heading descriptions, chapter notes, and ruling text. pgvector, Qdrant, or Weaviate for semantic similarity matching against prior CROSS rulings, internal approved classifications, and WCO Explanatory Notes content.
- Rules Engine: A custom Python service or decision-table rules engine for GRI sequencing, exclusion checks, legal note validation, and format checks – kept deterministic and entirely separate from the probabilistic LLM layer. This separation means the legal logic cannot be overridden by model outputs and produces consistent, auditable rule-application records.
- Governance and Integration: Role-based access control, SSO, versioned prompt and model logging, AES-256 encryption at rest and TLS in transit, and full audit log exportability. Integration layer: ERP connectors for SAP GTS and Oracle GTM, PIM data ingestion, customs platform webhooks, ABI-compatible filing workflows, and CSV import/export for teams not yet on API-connected systems.
What Results Does an AI HTS Code Classification Solution Deliver?

- Dramatically reduced classification time per SKU: By handling the research, attribute extraction, legal content retrieval, and draft rationale phases automatically, an AI-based HTS code classification system reduces the analyst time required per classification from hours to minutes. Teams process larger catalogs without proportional increases in broker fees or analyst headcount.
- Improved classification accuracy on routine and repeatable items: Grounding recommendations in authoritative tariff content and prior approved institutional decisions consistently outperforms reliance on individual analyst recall or recycled supplier codes – particularly for high-volume, lower-complexity classifications where human fatigue and inconsistency are the primary risk factors.
- Audit-ready documentation as a standard output: Every classification recommendation includes the source citations, GRI reasoning steps, alternative considered, and reviewer sign-off. This documentation package satisfies CBP reasonable-care requirements and substantially reduces the time and cost of responding to audit inquiries compared to reconstructing justifications after the fact.
- Lower duty leakage and overpayment risk: Incorrect classifications produce both under-payment exposure (penalty risk) and over-payment losses (paying higher duty rates than required). Systematic AI-assisted classification review identifies both types of error – recovering duty overpayments on existing inventory while preventing future underpayments that attract enforcement attention.
- Scalable response to tariff policy changes: When schedule updates or new trade policy layers affect existing product classifications, a system with versioned tariff data and a searchable product library can run an impact analysis across the entire active catalog, identifying affected SKUs automatically rather than requiring manual line-by-line review.
- Reduced dependence on external broker fees for routine work: Automated HS code classification with AI handles the research and documentation phases for high-confidence, repeatable items internally. Broker expertise is preserved for complex cases, novel products, and binding ruling requests where professional judgment genuinely adds value – rather than being consumed by routine lookups.
- Compound accuracy improvement over time: As approved decisions accumulate in the product library and reviewer feedback loops update the system’s institutional knowledge, classification accuracy on known-product categories improves progressively. The system gets faster and more consistent as the organisation’s own classification history grows.
- Reduced CBP examination rates for compliant importers: A consistent record of accurate, well-documented classifications contributes to lower CBP examination rates over time – reducing the ongoing operational cost of border delays, examination fees, and bond requirements that accompany a violation history.
Is an AI HTS Code Classification Solution Worth the Investment?
An AI tariff classification platform generates measurable return across several distinct cost and risk dimensions – making the business case substantially easier to build than for many AI investments, because the cost of the status quo is already quantifiable.
Key Business Metrics to Measure Before and After Implementation
- Classification cost per SKU: Measure the current all-in cost per classification including broker fees, analyst time, and rework. Compare against post-implementation cost once routine items are handled by the AI-assisted workflow. For organisations paying professional services rates on bulk classification work, this is often the single largest return driver.
- Classification error rate on filed entries: Establish a baseline by auditing a sample of prior filings against the correct HTS codes. Track post-implementation error rates on the same product categories. Even a modest reduction in error rate on high-duty-rate product lines produces significant financial impact when multiplied across filing volumes.
- Time to classification completion for new catalog items: Measure the calendar time from product onboarding to classified-and-filed status before and after implementation. For seasonal catalog importers and fast-moving ecommerce operations, this metric directly affects supply chain velocity and revenue timing.
- Audit response time and cost: Track the time and legal/consultant cost required to respond to CBP inquiries before and after implementation. Organisations with complete, source-cited classification documentation respond to audits in hours rather than days – a measurable operational cost reduction.
- Duty recovery from overpayment identification: Run a retrospective review of existing product classifications against the AI system’s recommendations. Many organisations discover duty overpayments on existing inventory classifications – recoverable through amended entries within the statutory correction window.
Realistic Implementation and Payback Timeline
Teams that have worked through this integration consistently find that the payback timeline depends heavily on two factors: catalog complexity and data quality. For a mid-size importer with a catalog of 500 to 2,000 active SKUs, a well-scoped implementation typically reaches operational steady state within three to six months. The first two months involve data preparation, system configuration, and initial product library population. Months three through six see the accuracy and speed gains materialise as the product library accumulates approved decisions. Full enterprise deployments with ERP integration and large catalog migrations require six to twelve months to reach full steady state.
The business case for acting now rather than waiting is straightforward: trade enforcement activity is at historically high levels, the de minimis exemption changes have eliminated duty-free treatment for approximately 1.4 billion packages per year – all of which now require full 10-digit HTS classification – and the WCO HS 2028 revision will require schedule-wide classification revalidation regardless. Organisations that build systematic classification infrastructure now will handle that upcoming reclassification cycle as a managed workflow rather than an emergency project.
What Does Implementing an AI HTS Classification Solution Actually Require?
What implementation experience reveals that theoretical explanations often miss is that the technical deployment of an AI classification system is rarely the hardest part. The harder challenges are data quality, organisational workflow integration, and establishing clear liability frameworks around AI-assisted decisions. Teams that plan for these factors from the outset reach steady state faster and with fewer corrections.
- Product data quality is the primary determinant of system performance: AI classification systems are only as accurate as the product descriptions they receive. Catalogs with vague descriptions (“component assembly”), missing material specifications, or undifferentiated variants across multiple product lines require a data enrichment phase before classification accuracy reaches reliable levels. Budget time for description normalisation upfront – it is not a technical task, it is an operational one.
- Compliance and legal liability framework: The importer of record remains legally responsible for classification accuracy regardless of any AI system’s recommendation. Organisations need a clearly documented internal policy establishing that AI outputs are advisory, that licensed professionals approve all filed classifications, and that override decisions are recorded with rationale. This framework satisfies CBP reasonable-care requirements and protects against liability ambiguity in the vendor relationship.
- ERP and customs platform integration complexity: Integration with SAP GTS, Oracle GTM, or customs filing platforms requires middleware configuration, data mapping, and testing. Simple API integration for standalone classification queries takes days to weeks. Full bidirectional ERP integration with automated duty-rate updates requires a more substantial technical project. Define the integration scope clearly before implementation begins.
- Tariff schedule maintenance and versioning: The system’s knowledge base – HTS schedules, legal notes, and policy layers – requires ongoing maintenance as the schedule is revised. Verify that the implementation plan includes a defined process for ingesting official schedule updates and revalidating affected classifications. A system running on a stale schedule version silently produces compliance risk.
- ABI certification requirements: Not all AI classification tools are certified for Automated Broker Interface filing. If the intended workflow includes direct ABI submission, verify certification status before vendor selection. An uncertified system that produces correct classifications but requires manual re-entry into an ABI-certified platform adds friction that affects operational ROI.
- Team expertise requirements and change management: Customs broker and compliance analyst acceptance of an AI copilot tool varies significantly based on how the tool is positioned and how reviewer workflows are designed. Tools that position AI as replacing expert judgment generate resistance; tools that position AI as eliminating low-value research tasks while keeping professionals in the decision seat generate adoption. Frame the implementation accordingly.
- Model accuracy ceiling and realistic expectations: Set internal expectations based on the actual state of the technology. The most accurate fine-tuned models on academic benchmarks currently reach approximately 40 percent fully correct 10-digit classification without human review. With well-designed human-in-the-loop review on flagged items and high-confidence batch processing on routine ones, operational accuracy in production environments is substantially higher – but “fully automated” 10-digit classification without expert oversight remains an unreliable approach for any high-stakes filing context.
Where This Solution Has Real Limits
- Genuinely novel products with no ruling precedent remain difficult for any AI system. When a new product type has no comparable CROSS ruling, no similar approved internal classification, and classification turns on an “essential character” judgment that requires customs expertise rather than legal text retrieval, AI accelerates the research phase but cannot substitute for a licensed professional’s determination.
- Vague or incomplete product descriptions defeat the system regardless of underlying AI capability. A supplier description of “plastic component” without material composition, functional purpose, or assembly context cannot be reliably classified by AI or humans. The system will correctly flag this for clarification – but if the supplemental information is not available, the classification remains uncertain.
- Rapid tariff schedule changes create a window of vulnerability between when a policy update is published and when the system’s knowledge base is updated. During this window, classifications in the affected chapters should be manually reviewed rather than relying on AI recommendations based on the prior schedule version.
- Multi-jurisdiction classification for the same product varies significantly between country-specific tariff schedules. A system optimised for U.S. HTS classification may not perform equivalently on EU Combined Nomenclature or other national schedules without separate configuration and knowledge base population for each jurisdiction.
Who Gets the Most Value from an AI HTS Code Classification Solution?
The organisations that benefit most from an AI-based HTS code classification system are those where classification volume is high, catalog complexity is significant, and the cost or risk consequences of errors are material. The solution delivers the strongest return where manual processes have already become a visible operational bottleneck – either because of cost, speed, or accuracy problems that are actively affecting the business.
- Mid-size to enterprise importers and manufacturers managing catalogs of hundreds to thousands of active SKUs, particularly those with frequent new product introductions or supplier changes that generate ongoing classification demand.
- Licensed customs brokerages looking to increase classification capacity without proportional headcount growth, especially those managing large multi-client portfolios where classification quality is a direct professional liability concern.
- Ecommerce and retail importers with high SKU velocity, seasonal catalog additions, and cross-border operations across multiple origin countries – where the volume of classification decisions makes manual approaches economically unviable.
- Trade compliance and logistics teams at companies with significant Chinese-origin product exposure, where Section 301 tariff complexity, de minimis changes, and audit enforcement risk create direct financial motivation for systematic classification improvement.
- Supply chain teams managing global sourcing portfolios that require consistent HS code classification across multiple trade lanes and destination jurisdictions for duty cost modelling and trade agreement eligibility analysis.
This solution is particularly valuable if: your team currently spends meaningful hours per week on routine classification research that could be systematically automated; your broker fees for catalog classification have become a material budget line; you have experienced a CBP penalty or audit inquiry related to classification errors; or you are facing an upcoming catalog expansion or tariff schedule change that your current capacity cannot absorb without external support.
Frequently Asked Questions About AI HTS Code Classification
Can an AI tool fully automate HTS classification without human review?
Not reliably for final filed classifications. The most accurate fine-tuned AI models on independent benchmarks currently achieve around 40 percent fully correct 10-digit classifications without human oversight – which means the remaining decisions carry real error risk. The practical answer is that AI can handle the research, attribute extraction, and draft recommendation phases automatically, while licensed customs professionals review and approve before CBP filing. This copilot model is what every serious vendor in the market advocates – not because AI lacks value, but because the importer of record remains legally responsible for accuracy regardless of what any system suggests.
How does an LLM for HTS classification in global trade operations differ from just using ChatGPT?
The critical difference is grounding and constraint. A general-purpose LLM operating on its training data will pattern-match to statistically common codes for a product description without applying the General Rules of Interpretation, checking legal notes, or referencing the specific heading exclusions that govern classification. Practitioner experience confirms that plain generative AI returns confident outputs that can fail CBP format validation or misapply chapter notes. A purpose-built LLM tariff classification platform grounds outputs in retrieved, versioned tariff content, applies GRI reasoning in sequence, and cites the specific legal sources supporting each recommendation. The architecture is fundamentally different – retrieval-first, rules-constrained, and explainable rather than statistically predictive.
What is a realistic AI import classification software ROI for a mid-size importer?
The ROI case rests on three measurable dimensions: classification cost reduction, error-penalty avoidance, and audit response efficiency. A mid-size importer currently paying professional broker rates for bulk catalog classification can model the cost reduction directly against current fee spend once routine items shift to AI-assisted internal review. Error-penalty avoidance is quantifiable from prior violation history or benchmark misclassification rates. Audit response efficiency – the time and consultant cost saved when documentation is pre-assembled versus reconstructed on demand – is typically underestimated in pre-implementation models but becomes one of the clearest post-implementation returns. Most organisations with significant classification volume reach payback within 12 to 18 months, though the timeline depends heavily on catalog size and data quality at implementation start.
What data does an automated tariff classification tool for trade compliance teams need to work accurately?
The minimum data required for reliable classification recommendations is a product description that includes material composition, primary function, and intended use – the attributes that actually determine which heading applies under the HTS. Physical form, country of origin, and part-versus-finished-good status are also important for many product categories. Supplier-provided product names alone are insufficient. Well-designed systems detect missing attributes and ask targeted clarifying questions before generating a recommendation, rather than producing a confident output from incomplete data. Organisations that invest in enriching product descriptions during implementation see substantially better accuracy outcomes than those that feed raw supplier catalog exports without normalisation.
How does an AI HS code platform for ecommerce and retail importers handle tariff schedule updates?
Schedule updates require the system’s knowledge base – including the HTS itself, chapter notes, and any affected policy layers – to be updated and versioned before new classifications are generated in the affected categories. Sound implementations maintain a formal schedule versioning process: official USITC updates are ingested, verified, and applied to a new knowledge base version, and previously approved classifications in affected chapters are flagged for revalidation. The system should not silently continue generating recommendations based on an outdated schedule. For organisations with large active catalogs, versioned tariff data and automated impact-analysis tooling are therefore not optional features but core operational requirements.
Build This Solution With Softlabs Group
Softlabs Group designs and builds custom AI HTS code classification solutions tailored to the specific product categories, trade lanes, regulatory jurisdictions, and internal systems your organisation operates. Rather than deploying an off-the-shelf tool that classifies against a generic knowledge base, we build a purpose-configured system grounded in your product data, your approved classification history, and the specific tariff schedules relevant to your import operations. Our enterprise AI development work in trade compliance spans the full pipeline: product data normalisation, knowledge base construction from authoritative regulatory sources, LLM reasoning layer configuration, confidence scoring and review workflow design, ERP and customs platform integration, and ongoing tariff schedule maintenance processes. We build for defensibility and auditability from the ground up – not as an afterthought.
If your team is managing growing classification volume, facing tariff complexity that manual processes cannot absorb, or looking to build the systematic documentation infrastructure that protects against CBP enforcement risk, the right starting point is a structured scoping conversation. Our team understands both the engineering requirements and the compliance context – and we build solutions that remain reliable as trade policy continues to evolve.