Executive Summary: Why Enterprise Knowledge Silos Cost More Than Most Organisations Realise
Your teams have answers somewhere – in a Confluence page someone updated six months ago, a Slack thread nobody bookmarked, or a policy document buried three folder levels deep in SharePoint. They also have employees spending significant time every week not finding them. An enterprise knowledge base LLM solution addresses this directly: instead of hunting across a dozen disconnected tools, employees ask a question in plain English and receive a precise, cited answer grounded in your actual company data – not generic internet knowledge from a model’s training set.
The cost is measurable – thousands of dollars per employee per year in lost productivity alone. But the less visible damage is often worse: decisions made on incomplete information, expertise that leaves when an employee does, and support teams that are slow to respond because they are still searching for the answer.
This page explains how a secure enterprise knowledge base LLM works from end to end – what it actually does under the hood, what it can realistically deliver, and what it takes to build one that holds up in production. The short version: it is not a chatbot sitting on top of documents. It is a permission-aware retrieval system with an AI language layer on top – and that difference is what determines whether it works or fails in a real enterprise environment.
Why Does Scattered Internal Knowledge Keep Getting Worse Without AI?
Scattered enterprise knowledge creates a productivity drain that worsens as headcount, tool sprawl, and document volume grow simultaneously.
Context: The Modern Enterprise Knowledge Environment
Most organisations run knowledge across 10 to 20 or more systems simultaneously – wikis, ticketing platforms, document stores, chat archives, email threads, and HR portals. Each tool operates as a silo with its own search interface, its own access rules, and its own organisational logic. Research from McKinsey Global Institute found that knowledge workers spend an average of 1.8 hours every day – nearly 9 hours per week – searching for and gathering information. At organisational scale, that figure represents an extraordinary amount of recoverable capacity sitting untapped.
When someone needs an answer on a deadline, they face three options: search each system manually, ask a colleague, or proceed without the full picture. All three carry a cost. The real problem is not that the information does not exist – it usually does. The problem is that nothing reliably connects a plain-English question to the right answer, inside the right permission boundary. That is exactly what a well-built enterprise knowledge base LLM solution does.
Key Pain Points This AI Solution Addresses
- Employees cannot find information across internal systems – leading to repeated questions, duplicated work, and decisions made without the right context, even when the answer already exists in a document somewhere.
- Knowledge siloed in individual brains and email threads – critical process knowledge, customer context, and institutional decisions live nowhere searchable, making them invisible to everyone except the person who holds them.
- New employee onboarding taking too long – new hires spend their first weeks asking colleagues for information that should be instantly findable, consuming time that experienced employees cannot afford to give.
- Customer support agents searching multiple systems for answers during live interactions, extending handle time and reducing first-contact resolution rates when customers need fast, accurate responses.
- Outdated knowledge base entries giving wrong answers – stale policy documents and superseded process guides erode trust in internal resources until staff stop consulting them entirely.
- Institutional knowledge lost when employees leave – without a searchable record of decisions, rationale, and expertise, organisations repeatedly solve problems their predecessors already solved.
- SharePoint search too poor to be useful for semantic queries, causing teams to bypass it entirely and revert to asking colleagues or accepting ignorance as the default.
Why Traditional Approaches Fall Short
Standard enterprise search returns links, not answers. The employee still opens five documents, reads them, and synthesises the relevant section manually – no faster than before the search ran. Adding more documents to a poorly searchable system makes the problem worse, not better.
Manual knowledge curation at scale is unsustainable. Dedicated knowledge managers cannot keep pace with the volume of content change across a growing organisation. Even well-maintained wikis drift out of date faster than any editorial team can address.
AI vs. manual enterprise search: manual search fails not because employees search poorly, but because enterprise content is too fragmented, too stale, and too permission-layered for any keyword search bar to navigate reliably. A properly implemented enterprise knowledge base LLM solution addresses each of these failure modes directly – by understanding the query semantically, checking permissions before retrieving, and generating an answer from verified evidence rather than returning a ranked list of links.
However, the comparison cuts both ways. Many AI knowledge tools that look strong in a controlled demo struggle in production because the fundamental issues – inconsistent permissions, stale content, poor document structure – were not addressed before deployment. The technology alone does not fix the underlying knowledge management problem; it amplifies what is already there, good or bad.
What Is an Enterprise Knowledge Base LLM Solution and What Does It Actually Do?
An enterprise knowledge base LLM solution connects company data sources, enforces access controls at every retrieval step, and generates cited answers in plain English – without copying sensitive data to shared external infrastructure.
The term AI knowledge base chatbotA conversational interface that retrieves and synthesises answers from enterprise documents, rather than answering from general model training knowledge describes only the visible surface of this technology. The deeper architecture is a permission-aware retrieval system. It uses a Large Language Model (LLM)An AI model trained on large text corpora that generates coherent, contextually appropriate language outputs from a given prompt strictly as a language layer sitting on top of search – not as the knowledge store itself. The model does not know your company’s data from training. It reads only the documents the retrieval layer surfaces for each specific query, from sources the requesting user is authorised to access.
This distinction matters a lot in enterprise settings. A system answering from general training knowledge will give you confident-sounding responses that are simply wrong about your specific policies, contracts, or internal processes. A properly grounded enterprise knowledge base LLM solution does not answer from memory. It only uses what it can retrieve – from sources the requesting user already has permission to access. That is what makes it trustworthy, not just impressive in a demo.
Most enterprise buyers are not actually purchasing an AI answer engine. They are purchasing a data quality, security, search-relevance, and change-management project with an LLM on top. Understanding this from the outset determines whether the deployment succeeds. An AI based knowledge management platform built on these principles delivers lasting value; one treated as a chatbot add-on typically fails within months as user trust erodes.
Vision and Objectives
- Employees receive precise answers grounded in current company documents, not plausible generalisations extrapolated from outdated training data.
- Every answer links back to the source document, allowing users to verify claims and navigate directly to the original for full context.
- User-level access controls inherited from every connected source system ensure no sensitive content ever surfaces to unauthorised users – at query time, not just at ingestion.
- Information search time per query drops from minutes of multi-system manual investigation to seconds of structured, permission-aware retrieval.
- Institutional knowledge captured in documents, tickets, chats, and wikis remains accessible after the employees who created it have left the organisation.
- The company knowledge base AI surfaces knowledge gaps – unanswered queries, weak source coverage, and stale content – giving knowledge management teams actionable intelligence on where to focus improvement efforts.
How Do Real Organisations Use an Enterprise Knowledge Base LLM Solution in Practice?
Customer Support Teams: Answers During Live Interactions
A support agent is mid-call when a customer challenges the refund terms on a promotional contract from eight months ago. The agent has never seen this specific contract type before. They place the customer on hold and open four systems.
Legacy enterprise search fails here because refund policies, contract amendments, and promotional terms are scattered across a CRM, a product wiki, email threads, and a legal folder nobody has organised in two years. The time spent finding the answer damages the interaction before the answer is even delivered.
An AI knowledge base solution for customer support teams retrieves the exact policy clause from the authorised source, with a citation, in seconds. The agent stays engaged. Handle time drops. Escalation rates decrease. And the organisation gains a searchable, auditable record of what information informed each response.
HR and New Employee Onboarding: Self-Service That Actually Works
A new hire in their third week still cannot locate the parental leave policy, the IT hardware request form, or the expense reporting deadline schedule. They ask their manager, who asks HR, who sends a link to a page that was last updated in 2021.
Traditional intranet solutions fail this scenario because documents sit in nested folder structures, search returns too many irrelevant results, and the “New Employee” wiki section drifts out of date within months of being created. The new hire’s first impression of the organisation’s knowledge systems is one of frustration.
An AI internal knowledge tool for employee self-service answers these questions instantly, in plain English, with citations back to current HR policy. Onboarding time shortens. Repetitive HR queries drop measurably. Experienced employees stop being interrupted to answer questions that should be self-serve.
Legal and Compliance: Document Retrieval at Audit Pace
A compliance officer needs to verify the organisation’s data retention policy, then cross-reference it against specific clauses in three vendor agreements – all ahead of a regulatory audit starting in 48 hours.
Manually, this task spans multiple repositories with inconsistent naming conventions, no version-control visibility, and no way to confirm which document version is current. Hours pass before the officer has the complete picture, and the margin for error is significant.
An LLM document search platform for legal and compliance treats this as a parallel retrieval task – pulling the relevant policy sections, contract clauses, and cross-references simultaneously, with citations to each source. The officer reviews verified evidence rather than reconstructing the picture from memory, and the audit response builds on a traceable, documented foundation.
Ready to explore what a private, permission-aware knowledge layer looks like for your organisation?
Talk to Our AI TeamHow Does an Enterprise Knowledge Base LLM Solution Actually Process and Retrieve Information?
The system ingests enterprise content, enforces permissions at every processing layer, retrieves relevant evidence, and generates answers only from sources the requesting user is authorised to access.
Knowing how each layer works also explains why cutting corners on any one of them produces exactly the failures teams consistently hit in real deployments. The architecture described here is not theoretical – it maps directly to the design decisions that determine whether a system passes a security review or fails one.

Data Acquisition: Where Enterprise Knowledge Comes From
The system connects to enterprise data sources through authenticated connectors. These cover SharePoint and OneDrive, Google Drive and Workspace, Confluence and Jira, Slack and Teams archives, email systems, ticketing platforms, HR portals, databases, and on-premise file servers. Each connector pulls content, file metadata, version timestamps, and – critically – the access permissions from the source system. The data and its access rules travel together. If a document is restricted to certain users in the source system, that restriction comes with it. This is the foundation everything else depends on.
The AI Processing Pipeline
- Secure Source Connection – The platform authenticates with each enterprise data source through secured, permission-preserving connectors. Source-level access metadata travels with every document from this point forward, establishing the trust chain that all downstream processing depends on. Without this step, the system cannot distinguish between what a user is and is not allowed to see.
- Content Extraction and Enrichment – OCR (Optical Character Recognition)Technology that converts scanned images and non-machine-readable documents into searchable, processable text handles scanned documents. Standard parsers process PDFs, spreadsheets, and other file formats. From there, the system removes duplicate content, flags sensitive material, tags metadata, and splits everything into searchable chunksSmaller, semantically meaningful segments of a document, typically 200-500 tokens, created to improve retrieval precision by matching query scope to content scope – typically 200 to 500 tokens each. In practice, teams consistently find that bad chunking and stale source documents cause more production failures than any model or architecture choice.
- Permission-Aware Indexed Storage – Each chunk gets converted into an embeddingA dense numerical vector representation of text meaning, enabling mathematical similarity comparison between queries and document chunks – a numerical representation of its meaning – and stored in the knowledge index alongside its metadata and access permissions. The content and its access rules are never separated. A Finance-only document stays Finance-only, right through to retrieval. This is the layer that prevents entitlement driftThe gradual accumulation of incorrect or outdated user permissions across enterprise systems, which becomes a critical security risk when AI retrieval amplifies the speed and scope of data access – the slow creep of wrong permissions that quietly breaks trust in many enterprise AI systems.
- Identity-Checked Hybrid Retrieval – When a query comes in, the system checks who is asking and what they are allowed to see before fetching anything. It then runs hybrid searchA retrieval approach combining vector-based semantic similarity search with traditional keyword matching, producing more accurate results than either method alone – keyword matching and semantic similarity together – applies metadata filters, and reranks results to surface the most relevant, permission-approved evidence. The user only ever gets content they are already authorised to see. This is not a setting that can be toggled off. It is enforced at the architecture level.
- Grounded Answer Generation – The LLM receives only the retrieved, permission-checked evidence as its context window. It generates an answer strictly from that material, not from general training knowledge. Each factual statement in the response traces to a specific source document, which the system surfaces as a citation the user can click through to verify. If the retrieval layer cannot find strongly relevant evidence, the system returns an honest low-confidence signal or “I cannot find a reliable answer” rather than a confident-sounding hallucination. That behaviour is a design requirement, not a limitation.
- Guardrails and Safe Delivery – Before the answer reaches the user, a multi-layer guardrails process runs. This checks for sensitive data exposure in the response, evaluates confidence thresholds against configurable policy, scans for prompt injectionA class of attack where malicious input manipulates an AI system’s behaviour by embedding adversarial instructions inside a user query or retrieved document attempts, and enforces compliance policy rules. Low-confidence responses and queries touching regulated content route to human review rather than being delivered as authoritative answers to the end user.
- Learn from Usage and Governance Signals – The system does not stay static after launch. Search logs, user feedback, unanswered query patterns, and audit trails feed back into retrieval tuning, index freshness schedules, and knowledge gap prioritisation. Over time this creates a cycle where the system gets more accurate, the knowledge coverage improves, and teams develop a clearer picture of where documented knowledge is weak.
Human-in-the-Loop: Where Human Judgment Still Matters
- Policy-sensitive and regulated queries – particularly those touching legal, HR, and compliance content – flag for human review before delivery, because the cost of a wrong answer in these domains exceeds the cost of a brief delay.
- Low-confidence retrievals, where the system cannot find strongly relevant evidence in the index, surface a clear uncertainty indicator or escalation path rather than delivering a speculative answer as if it were verified.
- Action-taking capabilities – submitting a ticket, updating a record, or triggering a workflow – require explicit user confirmation before execution. The system separates information retrieval from action-taking, and treats actions as a higher-confidence, higher-oversight category.
- Knowledge managers receive structured feedback from unanswered and poorly-answered queries, giving them a direct, data-driven view of where the knowledge base has gaps that content or source coverage improvements can address.
- The full audit log captures every query, retrieval, and answer in a verifiable chain – including a searchable answer history. Compliance teams get a traceable record of what information was accessed, what answer was generated, and when. This matters in regulated environments where demonstrating what the system said, and on what basis, is as important as the answer itself.
Output and Interaction: What Users Actually See
Users interact through a web interface, a Slack or Microsoft Teams integration, or a browser extension – depending on how the deployment is configured. Each answer arrives in plain English with inline citations linking to the source document. Users click through directly to verify context in the original file. Support team implementations surface answers inside ticket interfaces, so agents do not switch tools during live interactions.
Administrators get an analytics dashboard showing unanswered queries, knowledge coverage gaps, retrieval confidence trends, and usage patterns by team and topic. This turns the system into something that actively improves over time – showing exactly where the organisation’s documented knowledge is thin and where adding or updating content would have the most impact.
What Technologies Power a Private Enterprise LLM Knowledge Platform?
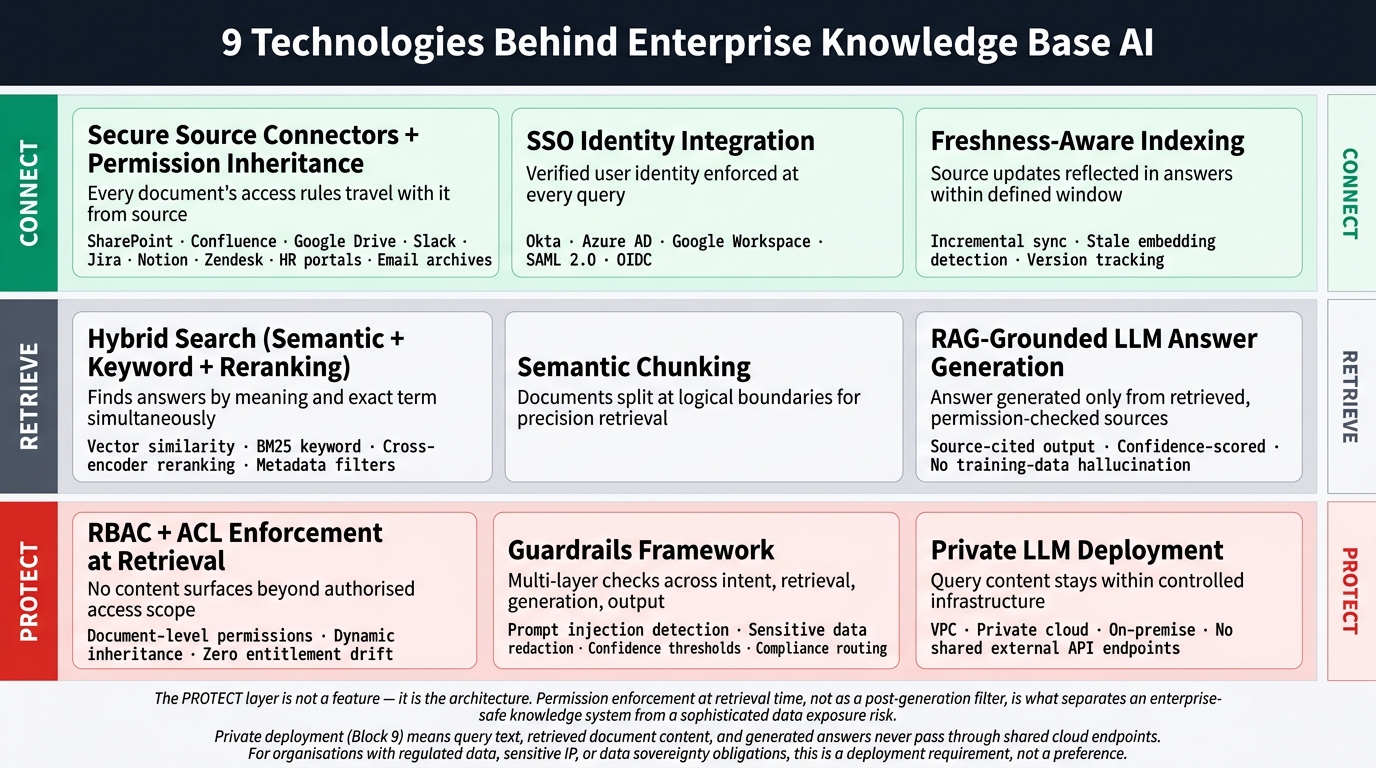
The core stack combines secure connectors, hybrid retrieval, private model deployment, and layered access controls – each component essential to enterprise-grade performance.
- RAG – Retrieval-Augmented GenerationAn AI architecture that grounds language model outputs in retrieved external documents, preventing hallucination by restricting the model to answer only from evidence it can retrieve at query time: The foundational architectural pattern behind every answer the system generates. Rather than relying on what the model learned during training, RAG retrieves specific, current documents at query time and constrains the model to answer exclusively from that material. This mechanism makes answers both current and verifiable – two properties a base LLM cannot provide alone.
- Hybrid Search: Combines vector-based semantic search with traditional keyword matching and a reranking pass across both result sets. Semantic search alone misses exact-match queries for specific terms, product names, or policy identifiers. Keyword search alone misses meaning and intent. Hybrid retrieval consistently outperforms either method in enterprise deployments where query types vary widely.
- Vector DatabaseA specialised data store that holds dense numerical vector representations of document chunks, enabling fast similarity search at the scale enterprise knowledge retrieval demands: Stores document chunk embeddings together with their metadata and permission data. Allows the system to run fast meaning-based search across a large index without slowing down as more content is added.
- Private LLM Deployment: For organisations handling regulated data, sensitive IP, or confidential HR and legal content, private LLM development keeps the model running on infrastructure the organisation fully controls – whether that is a VPCVirtual Private Cloud – an isolated cloud environment that keeps compute, storage, and network traffic separate from other tenants, giving organisations dedicated infrastructure within a cloud provider, a dedicated private cloud, or fully customer-controlled on-premise infrastructure. Query content never passes through shared external cloud endpoints. Open-source model options allow teams to operate the complete LLM knowledge base software stack within their own network perimeter, directly addressing the trust and data-residency concerns that block many enterprise adoption decisions.
- RBAC and ACL EnforcementRole-Based Access Control and Access Control Lists – permission frameworks that restrict data access to authorised users and roles, enforced here at the document-chunk level within the retrieval index: Document-level permission enforcement ensuring retrieval never surfaces content beyond the requesting user’s authorised access scope. Data at rest and in transit is encrypted throughout. This is the permission layer that separates an enterprise-safe knowledge system from a sophisticated data leak risk. Permissions must inherit dynamically from source systems, not be manually configured as a one-time setup.
- SSO – Single Sign-OnAn authentication protocol allowing users to verify identity once through a central identity provider, with that verified identity propagating to connected systems without repeated login steps Integration: Connects verified user identity from existing enterprise identity providers directly into the platform, ensuring every query carries accurate user context through the full retrieval and access-control chain. Without SSO integration, permission enforcement at retrieval time is not reliable.
- Semantic Chunking: The process of splitting documents at logically coherent boundaries before embedding, rather than cutting at arbitrary character counts. Well-designed chunks dramatically reduce context fragmentation during retrieval, improving the precision of which passage the system surfaces for a given query.
- Guardrails Framework: A multi-layer set of controls covering pre-retrieval intent and policy routing, retrieval-stage access enforcement, generation-stage groundedness verification, and post-generation confidence and safety checks. Sensitive-data redaction policies allow specific content patterns to be masked before an answer is shown to the user. This layered approach reduces hallucination risk, prompt injection exposure, and sensitive data surfacing across the full pipeline – not just at a single point.
- Freshness-Aware Indexing: The index does not just get built once. Sync schedules and content freshness controls ensure that when a source document is updated, the indexed version reflects that change within a defined window. Stale embeddings are one of the most common causes of wrong answers in production – this is the mechanism that prevents them from silently accumulating.
What Results Does an Enterprise Knowledge Base LLM Solution Deliver?

An enterprise knowledge base LLM solution cuts information search time, reduces avoidable support ticket volume, and preserves institutional knowledge that would otherwise disappear when experienced employees leave.
- Recovered employee search time at scale – employees stop spending close to two hours every working day hunting across systems. That time returns to actual work. At any meaningful headcount, the recovery is significant and it shows up in output, not just in a survey.
- Reduced support ticket volume and handle time – an AI knowledge base chatbot layer handles repetitive policy and process queries from employees and customers, reducing the load on IT, HR, and operations support teams. Agents who do handle live queries have answers available immediately, cutting average handle time measurably.
- Faster new employee onboarding – new hires access accurate, cited answers to operational questions on demand, 24 hours a day, without consuming manager or colleague time. Onboarding ramp-up time shortens, and new employees develop independent working capability faster.
- Preserved institutional knowledge across staff turnover – the company knowledge base AI indexes and makes permanently searchable the documents, decisions, process notes, and expertise that previously existed only in individual employees’ heads or private email threads.
- Auditable compliance and legal knowledge retrieval – compliance and legal teams locate specific policy, contract, and regulatory terms in seconds rather than hours, with citations and version information that support confident, defensible audit responses.
- Proactive knowledge gap identification – query analytics surface topics where the system cannot find strong evidence, pointing directly to content gaps. Knowledge management investment concentrates where retrieval data shows the greatest need, not where teams guess it might be useful.
- Continuous retrieval quality improvement – usage logs, feedback signals, and unanswered-query patterns feed back into retrieval tuning, freshness monitoring, and content improvement cycles. The AI powered knowledge base for enterprises improves in value over time rather than depreciating.
- Role-specific copilots for different teams – the same underlying knowledge layer can power tailored experiences for support, HR, legal, operations, and internal IT teams. A support agent’s copilot surfaces ticket-relevant knowledge. An HR copilot handles policy and onboarding queries. A legal copilot retrieves contract and compliance references. Each team gets answers relevant to their context without needing a separate system.
- Unified access across a centralised enterprise knowledge base – rather than maintaining separate wikis, portals, and search tools each covering a partial view of company knowledge, a centralised AI based knowledge management platform delivers one access point across all connected sources, with consistent permission enforcement and a single interface for every user regardless of which underlying system holds the answer.
Is an Enterprise Knowledge Base LLM Solution Worth the Investment?
Yes – a properly implemented enterprise knowledge base LLM solution generates measurable ROI primarily through recovered employee productivity and reduced support costs. For most organisations, the earliest indicators become visible within the first few months of full deployment, as search time data and ticket volume trends begin to accumulate.
Key Business Metrics to Measure Before and After Deployment
The business case comes down to five areas where the impact is measurable. Before deployment, track the current state across each. After deployment, measure again at 90 and 180 days.
- Employee information search time – Record how long employees spend searching across systems today, then track the reduction after deployment by role and team. McKinsey’s research puts the current average at 1.8 hours per day per knowledge worker spent searching and gathering information. Even cutting that by a third, across a team of 200, adds up to a significant amount of recovered working time every month.
- Internal support ticket volume – Count the IT, HR, and operations tickets that exist simply because someone could not find an answer on their own. A well-maintained knowledge layer with good connector coverage typically deflects a meaningful share of these – though the exact number depends on content quality and how consistently staff are directed to the system before submitting a ticket.
- New hire time to independent productivity – Track how many weeks pass before a new employee can work without asking colleagues for guidance on routine process and policy questions. An AI knowledge management solution for onboarding and training shortens this window by giving new hires accurate, cited answers on demand. The saving comes from both sides: the new hire ramps up faster, and experienced colleagues get fewer interruptions.
- Compliance and audit preparation time – Log the hours legal and compliance teams spend locating specific policy documents, contract terms, and regulatory references before audits and reviews. Centralised, searchable retrieval collapses this from days to hours for many organisations.
- Knowledge duplication and re-creation cost – Estimate how frequently teams recreate analysis, reports, or process documentation that already exists somewhere in the organisation. Making existing knowledge findable directly reduces this category of waste, which is consistently underestimated in cost analyses.
Realistic Implementation and Payback Timeline
A common pattern across real implementations of this solution is a 6 to 12-week initial phase covering connector setup, permission configuration, content quality review, and retrieval baseline testing – followed by a 3 to 6-month optimisation period where query feedback and analytics drive measurable improvement. For a mid-size organisation with 4 to 8 primary knowledge sources, the initial measurable ROI case typically becomes visible within the first 60 to 90 days of full deployment, as ticket deflection and search time data accumulate.
The case for acting now rather than waiting rests on a simple compounding dynamic: every month without a structured retrieval layer is a month of search time the organisation cannot recover. The longer the knowledge landscape grows unchecked, the more ingestion, deduplication, and permission-audit work accumulates before deployment can even begin.
What Does Implementing a Secure Enterprise Knowledge Base LLM Actually Require?
A secure enterprise knowledge base LLM deployment requires clean data governance, enforced permissions, and ongoing operational management – not just model selection and connector setup.
- Permission infrastructure must be audited before ingestion begins. Entitlement drift – where access rules in source systems no longer reflect who should actually see what – flows directly into the AI retrieval layer. If it is wrong at the source, the AI will surface restricted content to people who should not see it. Fixing permissions before deployment starts is a prerequisite, not a later task.
- Content quality determines answer quality. Stale, duplicated, or poorly structured documents produce stale, inaccurate answers regardless of how sophisticated the retrieval architecture is. Organisations need to plan a content hygiene phase – deduplication, freshness review, metadata tagging, and sensitivity classification – as part of the deployment project, not after it.
- Integration complexity scales with source system count. Connecting three well-maintained tools through modern APIs is straightforward. Connecting 15 to 20 tools with inconsistent file formats, legacy structures, irregular permission models, and different update schedules takes considerably more engineering work and a longer testing phase. The effort is manageable – but it should be scoped honestly at the start.
- Private deployment architecture may be mandatory for regulated content. Organisations handling regulated data, proprietary IP, or sensitive HR and legal content need to run the model on their own infrastructure rather than routing query context through shared cloud endpoints. This is where a custom enterprise AI development approach differs from purchasing a packaged SaaS product – the deployment model is configurable to the organisation’s actual compliance requirements.
- Ongoing maintenance is an operational requirement, not one-time setup. Embeddings go stale as source documents change. Retrieval quality drifts as content volume and structure evolve. Regular reindexing schedules, freshness monitoring, search log analysis, and feedback loop processing are permanent operational functions, not configuration steps completed at launch.
- User adoption requires active change management. What implementation experience reveals that theoretical explanations often miss is this: the technology rarely fails enterprise deployments – adoption does. Teams default to old habits within weeks of launch unless they receive clear use-case framing, hands-on training with their actual query types, and visible executive sponsorship signalling that the system is the expected path to answers.
- Realistic deployment timelines assume enterprise complexity. A working prototype can be demonstrated quickly. A production system with full permission inheritance, connector coverage, guardrails, governance, and performance baselines takes 3 to 6 months for initial deployment and 6 to 12 months to reach optimised operational maturity at enterprise scale.
Where This Solution Has Real Limits
- The system cannot answer reliably from undocumented knowledge. If the answer lives exclusively in a colleague’s head and has never been written down or recorded anywhere in a connected source, no retrieval architecture can surface it.
- Retrieval quality falls when source content is poorly maintained. A knowledge base full of outdated policies and contradictory documents will return outdated, contradictory answers – often presented with the same confidence as a well-sourced one, because the system does not know the underlying content is wrong.
- Highly ambiguous queries with no strongly matching documents in the index produce low-confidence or unhelpful responses. The system augments human expertise; it does not replace domain specialists on genuinely novel or complex analytical questions with no documented precedent.
- Permission inheritance across legacy systems with non-standard access models requires custom engineering. Some source systems do not expose clean permission APIs, and accurately replicating access rules for these systems adds technical complexity and project time.
Which Organisations Benefit Most from an AI Knowledge Base Platform?
Organisations that get the most from a secure enterprise knowledge base LLM tend to share a few traits: knowledge is spread across many disconnected systems, teams spend significant time each day looking for answers they know exist somewhere, and the cost of a slow or wrong answer is real – in customer experience, compliance exposure, or straightforward lost productivity. An AI based knowledge management platform becomes most valuable when several of these conditions exist together.
This solution is particularly valuable if:
- Your organisation runs 10 or more knowledge sources with no unified search experience, causing employees to switch between tools for every information task.
- Customer support, HR, IT helpdesk, or legal teams handle high volumes of repetitive internal queries that consume specialist time answering questions already documented somewhere.
- New hire onboarding productivity is measurably impacted by information inaccessibility – new employees ask experienced colleagues for guidance on matters that should be self-service.
- Your industry carries compliance obligations requiring auditable, citation-backed answers – healthcare, financial services, legal, manufacturing, or any regulated sector where documented evidence of what information was accessed and when matters.
- Institutional knowledge loss from staff turnover has created visible operational gaps, where critical process knowledge left with specific individuals and was not recovered.
- Your current approach to internal knowledge management is telling employees to search SharePoint or Confluence – and they have stopped, because the search quality is too poor to be useful.
Ideal buyer profiles for an AI private internal knowledge tool deployment include Knowledge Management Directors, CIOs, VP of Operations, IT Service Management leads, Head of HR Operations, and Chief Compliance Officers – typically in mid-size to large organisations where knowledge complexity has outgrown what any single team can manually curate or any standard search bar can reliably surface.
Frequently Asked Questions About Enterprise Knowledge Base LLM Solutions
How is an enterprise knowledge base LLM platform for large companies different from standard enterprise search?
Standard enterprise search returns a ranked list of links. The employee still opens several documents, reads through them, and extracts the relevant section manually – barely faster than not searching at all. An enterprise knowledge base LLM platform reads the retrieved evidence and gives a direct answer in plain English, with citations back to the source. The LLM does not answer from its general training knowledge. It answers only from what the retrieval layer finds for that specific query – from sources the requesting user is already allowed to access. That makes the response actually useful rather than just a starting point for more manual work.
How does an AI powered internal search platform for enterprise teams keep sensitive company data private?
The strongest implementations run the language model on the organisation’s own infrastructure or a private cloud environment – so query content never touches a shared external server. On top of that, permission-aware retrieval means the system only ever shows each user content they are already authorised to see in the source system. Identity is verified through SSO at every query, and access rules from each connected source are enforced at the retrieval step. Some designs go further and avoid maintaining a separate indexed copy altogether, retrieving directly from source systems in near real time – which reduces the amount of data that ever leaves its original home.
Can an AI knowledge management solution for onboarding and training actually reduce new employee ramp-up time?
Yes, noticeably. In the first few weeks, new hires spend a lot of time chasing down HR policies, IT request forms, expense procedures, and process guides – asking managers and colleagues who then have to stop their own work to help. An AI internal knowledge tool for employee self-service gives new hires accurate, cited answers on demand at any hour, without pulling anyone else into it. The same questions still get answered correctly. They just get answered faster, and without the back-and-forth. Organisations that track how long it takes a new hire to work independently typically see that window shrink when self-service knowledge actually works.
What happens when an LLM document search platform for legal and compliance cannot find a reliable answer?
A well-built system says “I don’t know” rather than inventing an answer. If the retrieval layer cannot find strong enough evidence to answer the question, the system tells the user it cannot find a reliable answer and suggests where to look instead. For high-stakes queries, it routes to a human reviewer rather than guessing. In regulated environments – legal, compliance, finance, healthcare – a clear “not found” is far safer than a confident answer built on weak evidence. The ability to say “I don’t know” is not a flaw. It is one of the most important things to test before going live.
How does enterprise AI search software reduce information silos when systems like SharePoint, Jira, and Slack each have separate access rules?
The connector layer pulls content from each source system while keeping that system’s permission rules intact. SharePoint access restrictions, Jira project permissions, and Slack channel membership all come across with the content and stay attached to it in the retrieval index. When a query comes in, the system checks who is asking before it fetches anything. The user sees one search interface covering all connected sources – but what each person can see is still governed by the same access rules as in the original system. For SharePoint specifically, where native search quality is notoriously unreliable, this approach means better search without needing to change how permissions are managed.
Build This Solution With Softlabs Group
Softlabs Group builds enterprise knowledge base LLM solutions around each client’s actual setup – their data sources, access control model, compliance requirements, and the workflows where finding information is slowest. We start with your specific knowledge landscape and engineer the retrieval architecture, connector layer, guardrails, and deployment model to match it. We do not configure a packaged product and hand it over. For organisations with regulated content, sensitive IP, or data sovereignty requirements, we build on private LLM deployment architectures that keep all queries and retrieval inside your controlled environment.
If your teams are spending real time searching for answers that already exist somewhere in your systems, that is a solvable problem. The first step is a straightforward conversation about your knowledge landscape, your biggest friction points, and what you need from a deployment to actually trust it. No obligation, no sales pitch – just a direct technical discussion about what would work for your organisation.