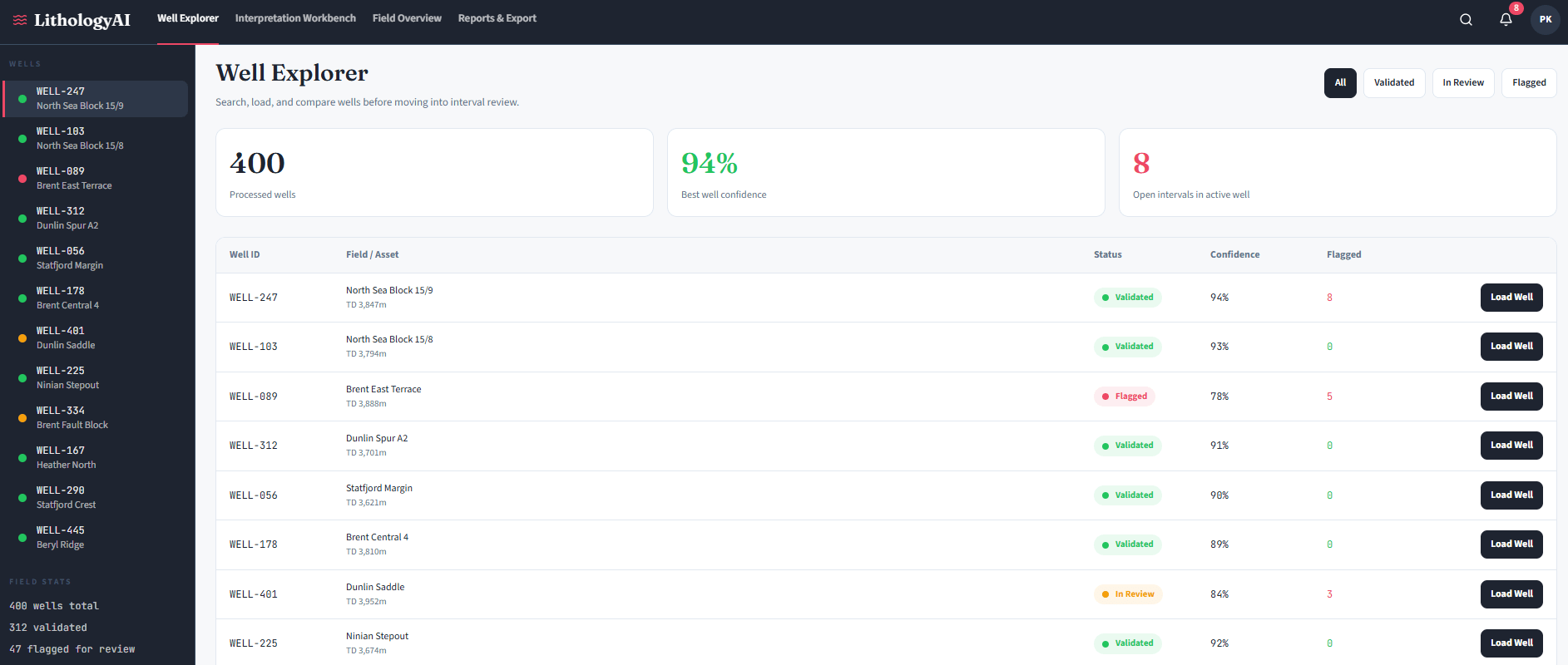
Executive Summary: AI Delivers the Formation Evaluation Speed That Manual Interpretation Never Could
A petrophysicist staring at 400 wells worth of gamma ray, resistivity, and density logs – with a field development decision due in three weeks – understands the gap between what the data holds and what manual analysis can deliver. The AI Assisted Lithology Prediction Solution closes that gap by automating first-pass rock-type classification from well log data, turning days of specialist interpretation into hours of reviewed, validated output.
The approach does not aim to replace the geologist. Instead, it handles the structured, repetitive workload that consumes the majority of a skilled petrophysicist’s project time – so their remaining effort concentrates on decisions that genuinely require human judgment. Supervised machine learning, transformer-based architectures, and SHAP explainability applied to wireline log data produce lithology classifications with confidence scores and feature contribution weights at every depth point. The result is faster drilling decisions, consistent multi-well correlation, and an interpretation workflow that scales with data volume rather than headcount.
1. The Challenge: Why Does Manual Lithology Interpretation Keep Failing at Scale?
Manual lithology interpretation fails at scale because data volume, specialist scarcity, and interpretation subjectivity compound faster than any team can manage.
Context: Formation Evaluation in Modern E&P Operations
The exploration and production industry depends on accurate lithologyThe classification of rock types at depth – sandstone, shale, carbonate, evaporite, and mixed facies intervals – derived from geophysical well log measurements to drive every downstream decision: well placement, completion design, reservoir modelling, and production forecasting. In a mature basin with hundreds of drilled wells, the well log archive represents decades of subsurface intelligence waiting to be extracted. But extracting that intelligence requires skilled petrophysicistsSpecialists who analyse physical and chemical properties of rocks from borehole measurements to evaluate formation characteristics and hydrocarbon potential to manually work through thousands of depth intervals across multiple log curves. That process does not scale.
Data is accumulating faster than experienced interpreters can handle it. Backlogs grow, quality varies between individuals, and teams end up choosing between speed and rigour. Neither is acceptable when a wrong lithology call can cost millions in completion errors or missed pay zones.

Key Pain Points This AI Solution Addresses
- Geoscientists spending too long on manual log interpretation: A full petrophysical evaluation of a single well – covering all standard log curves, quality control, normalisation, and cross-plot interpretation – is a multi-day specialist task. Across a 200-well field, the cumulative workload routinely extends into months or years of specialist time before any reservoir model update can begin.
- Well log data volumes too large for manual analysis: As digital archives grow, legacy well reinterpretation projects routinely exceed team capacity by years. Data sits uninterpreted while drilling and investment decisions wait.
- Inconsistent lithology interpretation across teams: Two petrophysicists applying different gamma ray thresholds to the same well data will produce different results. Multiply that across a team over several years, and the formation model becomes internally inconsistent – which means reservoir simulations built on it are unreliable too.
- Shortage of experienced petrophysicists: Skilled formation evaluators take a decade to develop. The talent supply has not kept pace with global drilling activity or the reinterpretation demand of mature field redevelopment programs.
- Slow drilling decisions due to manual interpretation: Wellsite geologists needing near-real-time lithology during geosteeringThe practice of adjusting a directional well’s trajectory in real time based on formation data, to keep the drill bit within the target reservoir interval operations cannot wait for a full petrophysical workflow to complete. Delays translate directly to incorrect well placement and costly sidetracks.
- Subsurface data siloed across multiple formats: Well logs exist in LAS filesLog ASCII Standard files – the industry-standard text format for storing wireline well log data, containing depth-indexed measurements from downhole sensors, PDF reports, raster scans, and proprietary software exports. Consolidating these for any multi-well analysis requires significant manual effort before interpretation even begins.
- Legacy software not handling large well data volumes: Most petrophysical workstations operate well on individual wells but struggle to scale to basin-wide analysis or machine learning workflows without significant engineering overhead.
Why Traditional Approaches Fall Short
Manual interpretation introduces three failure modes that become increasingly costly at scale. First, subjectivity compounds across teams and time. Gamma ray thresholds for sand-shale discrimination, resistivity cut-offs for pay identification, and cross-plot interpretation all reflect individual training and experience. A formation model built by three petrophysicists over five years contains systematic inconsistencies that invalidate direct well-to-well comparisons.
Second, the preprocessing burden is invisible but enormous. Before any interpretation begins, a petrophysicist must validate log quality across multiple tool vintages, normalise curves for vendor differences, handle washout zones and spike artefacts, and align depths across different logging passes. Most teams underestimate this. Experienced practitioners consistently report that this validation step – not the interpretation itself – takes up most of the project time, especially on legacy datasets covering multiple operators and tool generations.
Third, manual workflows do not get faster with experience. Every new well requires the same setup effort regardless of how many wells the team has already done. An AI approach reverses this: each additional labeled well improves the model rather than adding to the backlog. In practice, teams deploying AI lithology tools for the first time typically find that data quality issues consume more project time than the machine learning itself. The preprocessing pipeline, not the model, is where most of the effort goes.
2. The AI Solution Concept: What Does an AI Assisted Lithology Prediction Solution Actually Do?
An AI Assisted Lithology Prediction Solution automates rock-type classification from well log data, replacing subjective visual interpretation with reproducible, data-driven outputs.
The system applies supervised machine learning to wireline log curves – the physical measurements recorded as a logging tool moves through a borehole. By training on wells with verified lithology – confirmed by physical core sample analysis – it learns to recognise the log response patterns corresponding to each rock type: sandstone, shale, carbonate, evaporite, and complex mixed-facies intervals. Once trained, the AI formation evaluation software classifies thousands of depth points per well in seconds rather than days.
The system sits between raw log data and the geologist’s workstation. Critically, it does not produce a final interpretation. It delivers a first-pass classification with confidence scores and feature contribution weights at every depth – a structured starting point the geologist reviews, challenges, and approves. This approach works better in practice than systems that try to remove the geologist entirely. The principle that holds across every successful deployment: AI handles the first 80 percent of the workload, and the geologist focuses on the complex 20 percent that actually requires human judgment.
Vision and Objectives
- Compress multi-well lithology interpretation from months to days by automating first-pass classification at scale across full field archives
- Deliver consistent, reproducible rock-type classification across all wells in a field or basin – so different geologists interpreting the same data reach the same conclusions
- Surface uncertainty explicitly at every depth point – directing geologist attention to the intervals that genuinely require specialist review rather than distributing it uniformly across all depths
- Reduce preprocessing effort through automated data quality detection, curve normalisation, and missing-curve handling – solving the problem that currently consumes most of the project timeline before interpretation begins
- Provide auditable, explainable outputs showing which log curves drove each classification decision, enabling confident sign-off and defensible reserves reporting
- Integrate with existing petrophysical and geological modelling workflows without requiring data re-export, manual format conversion, or workflow redesign
3. Real-World Application Scenarios
Mature Field Reinterpretation: The E&P Asset Team
A 400-well legacy field has never had a consistent petrophysical framework applied across its full 30-year drilling history – and a new infill program now depends on a reliable basin-wide formation model that doesn’t yet exist.
The conventional approach requires a specialist team working for 18 months to achieve even basic log consistency across different vintages, operators, and tool vendors. The AI petrophysical analysis software pipeline ingests all 400 wells simultaneously, runs automated quality detection, normalises logs to a common reference, and delivers a first-pass lithology classification with confidence scores within days – not months. The asset team reviews flagged uncertainty intervals, validates against held-out blind wells, and feeds the consistent interpretation into the reservoir model. The infill program launches on schedule. Approximately 80 percent of the manual interpretation workload is eliminated, and the team’s petrophysicists focus on the genuinely complex stratigraphic intervals the system identified as uncertain.
Real-Time Geosteering: The Wellsite Geologist
At 2am during a directional drilling run, the wellsite geologist needs to know whether the bit is still in the target sandstone or has already entered an overlying shale – and the next casing point decision is three hours away, with no wireline data available.
Post-drill logs won’t help. The only available data streams from the downhole MWD and LWD tools. A well log interpretation tool processing real-time resistivity, gamma ray, and drilling parameter feeds classifies each new depth increment as it arrives, generating a continuously updated lithology prediction with uncertainty flags. When confidence drops and the log signature shifts, the system alerts the wellsite geologist immediately – not hours later. The geosteering decision remains with the human. However, formation exit events that previously went undetected for tens of metres now get flagged within minutes of the bit crossing the boundary.
New Acreage Evaluation: The Exploration Geologist
An exploration geologist has 90 days to rank 15 prospect locations across a new basin entry, working from 80 legacy wells drilled by previous operators over 20 years – data that has never been consistently interpreted, carries no unified formation naming convention, and lives in four different software formats.
Running the AI subsurface analysis platform across all 80 legacy wells in batch mode establishes a consistent electrofaciesRock types defined by their distinctive well log response patterns, rather than by physical core description alone – enabling systematic formation classification across wells without core data at every well framework for the basin in days. The automated correlation panel shows which wells share the same reservoir formation, identifies stratigraphic pinch-outs across the acreage block, and highlights intervals where model uncertainty is highest – flagging the specific wells that need detailed manual review before the prospect ranking is finalised. The geological AI prediction tool completes approximately 70 percent of the preliminary well correlation work, allowing the exploration team to focus the remaining time on the stratigraphically complex intervals the system itself identified as requiring human interpretation.
Ready to explore what this solution looks like for your organisation?
Talk to Our AI Team4. How It Works: Inside the AI Assisted Lithology Prediction Solution Pipeline
Each stage in the pipeline addresses a documented failure point – either in manual workflows or in earlier automated attempts that ignored data quality, missing curves, or geologist trust. The sequence below shows data moving from raw LAS files to a reviewed, validated lithology strip ready for the reservoir model.
Data Acquisition: Well Log Inputs and Ground-Truth Sources
The system ingests well log data covering gamma rayA log measuring natural radioactivity in formations – high gamma ray readings typically indicate shale, while low readings indicate clean sands or carbonates, spontaneous potential, resistivityLogs measuring a formation’s resistance to electrical current – high resistivity can indicate hydrocarbons or tight formations; low resistivity typically indicates water-saturated or shaly zones (shallow, medium, and deep), bulk densityA measurement of formation density derived from gamma-gamma radiation scattering, used to calculate porosity and identify lithology alongside neutron porosity readings, neutron porosityA log measuring hydrogen content in formations, primarily reflecting pore fluid volume – used in combination with bulk density to identify lithology and gas-bearing intervals, sonic transit timeA measurement of the time taken for sound waves to travel through a formation, used to calculate porosity, identify lithology, and calibrate seismic data, caliper, and photoelectric factor curves where available.
Additional inputs include core sample descriptions providing verified lithology labels for training, mud logs with drilling parameters, and – where available – core images for computer vision-based classification of cutting samples. Real-time logging-while-drillingDownhole measurement technology that records formation data in real time as the drill bit advances, enabling formation evaluation decisions during active drilling without waiting for wireline runs data streams feed the system during active drilling operations, enabling near-wellbore classification to support geosteering without waiting for post-drill wireline runs.
The AI Processing Pipeline
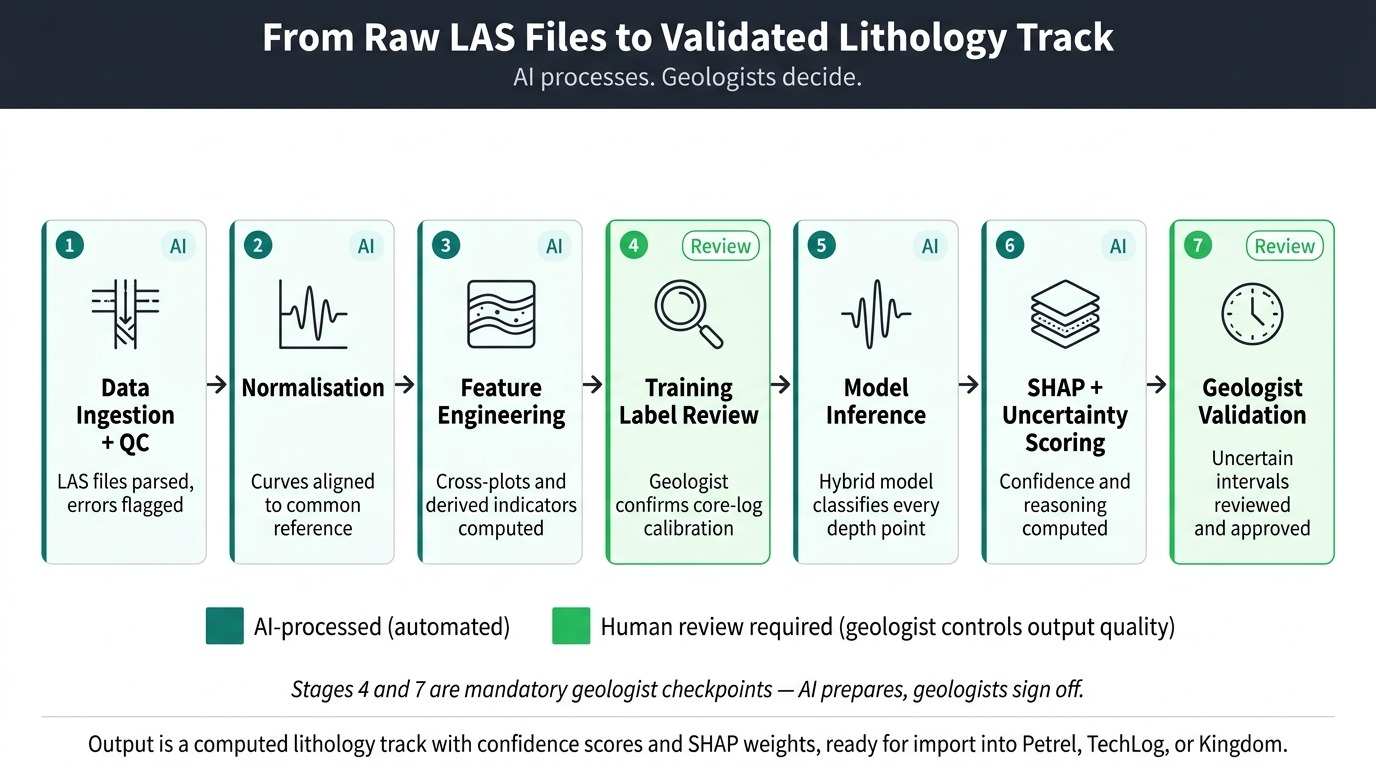
- Data Ingestion and Automated Quality Control: First, the system parses well log files and runs automated rule-based quality checks across all curves. Density spikes, resistivity saturation clipping, sonic cycle-skipping errors, and washout-zone anomalies trigger automated flags – directing human review before any machine learning begins. This step frequently identifies data problems that manual inspection at scale consistently misses, including systematic digitisation errors in pre-1980s logs and sensor failures in specific depth intervals.
- Log Normalisation and Depth Alignment: Next, the pipeline corrects for systematic differences between tool generations, logging vendors, and measurement runs. Depth misalignment across multiple logging passes gets resolved, and curves normalise to a common reference range. Without this step, the model trains on systematic vendor biases rather than genuine lithological signals – producing predictions that degrade as soon as the system encounters wells from a different operator or tool configuration.
- Feature Engineering and Class Balancing: Once normalised, the system computes derived features: RHOB-NPHI separationThe computed difference between bulk density and neutron porosity measurements – a key discriminator for gas-bearing zones and lithology type that petrophysicists use in cross-plot analysis, M-N cross-plot values, and other indicators that petrophysicists routinely use in manual interpretation. The pipeline then applies SMOTE-TomekA combined resampling method that first oversamples rare classes using synthetic generation (SMOTE) and then removes noisy borderline samples (Tomek Links) – more effective than plain SMOTE for high-dimensional log data to address class imbalance, because thin carbonate or evaporite intervals are rare in training data but critical to predict correctly.
- Hybrid Model Inference: The system runs three model types in combination: a gradient-boosted ensemble for tabular log data, a transformer-based sequence modelA neural network architecture using self-attention mechanisms to read patterns across long sequences – applied to well logs, it captures stratigraphic trends across hundreds of metres of depth that reads depth trends across hundreds of metres, and a 1D convolutional neural networkA neural network that applies filters along a one-dimensional depth sequence to detect local patterns in log curves – effective at capturing sharp formation boundaries and thin-bed anomalies that picks up sharp local log-response spikes. Each architecture catches what the others miss. The transformer handles wells with missing curves through attention maskingA technique that restricts the model’s attention to only the log curves actually present in a given well, rather than imputing false values for missing measurements – enabling robust performance on incomplete legacy log suites – working only with the curves that actually exist rather than inventing values for absent ones.
- SHAP Explainability Scoring: At this stage, the system computes SHAP contribution weightsSHapley Additive exPlanations – a game-theoretic method assigning each input feature its marginal contribution to a specific prediction, producing ranked contribution scores that make model decisions auditable and contestable for every depth-point prediction. Each classified interval receives a ranked breakdown showing which log curve contributed what percentage – for example, gamma ray 42 percent, resistivity 31 percent, bulk density 18 percent. Geologists can examine this reasoning chain, contest a specific call, and sign off on the output with a documented evidence trail. Without this layer, senior geologists reject AI outputs on principle – and they are right to do so.
- Uncertainty Quantification: The system generates Bayesian posterior probabilitiesProbability distributions across all candidate classes produced by Bayesian inference, reflecting the model’s confidence level given the evidence – at each depth point, the system outputs a probability for each lithology class rather than a single label rather than single-point class labels. Every depth interval receives a confidence score, and intervals falling below a configurable confidence threshold get flagged for mandatory human review. Surfacing uncertainty aggressively – rather than hiding it behind a confident wrong prediction – is what converts sceptical senior geologists into active users.
- Output Assembly and Delivery: Finally, the system assembles a structured lithology strip with confidence heatmaps, uncertainty flags, and SHAP contribution charts at each depth. Outputs format for direct import into standard geological modelling workflows, with no manual reformatting required. Multi-well correlation panels show formation boundaries and lithology consistency across the field in a single view.
Human-in-the-Loop: Where Human Judgment Still Matters
Every team that has integrated AI lithology outputs into real petrophysical workflows reaches the same conclusion: the geologist sign-off stage is not a bottleneck to eliminate. It is the quality gate that makes outputs defensible in front of a reservoir committee or partner review. The system is designed to make that review efficient – not to skip it.
- All depth intervals below the confidence threshold require geologist review and explicit override before outputs pass downstream into reservoir models or completion plans
- Core-to-log calibration decisions – selecting which core intervals serve as training labels and how to handle core-log depth shifts – require petrophysicist judgment and cannot be automated reliably
- Basin-level geological consistency checks, such as verifying that a predicted formation boundary aligns with known regional stratigraphy, remain a geologist responsibility throughout the workflow
- In geosteering applications, the real-time classification output serves as an advisory alert – the wellsite geologist retains full authority over all directional drilling decisions
- Final sign-off on lithology interpretations before they feed reserves certification or joint venture reporting sits with a qualified petrophysicist at every stage
Output and Interaction: How Results Are Delivered
Outputs appear in the geologist’s workstation as a computed lithology track alongside the original log curves – the same format as a manually created interpretation, but with confidence scores and SHAP contribution charts attached. A separate uncertainty heatmap highlights the depth intervals that need human review, while high-confidence zones show as validated. Multi-well projects generate correlation panels showing formation boundaries and lithology consistency across the full field.
For drilling teams, a lightweight real-time dashboard displays the current lithology classification, confidence level, and the distance to the nearest formation boundary as the drill bit advances – updating on each new data transmission from the downhole tool.
5. What Technologies Power an AI Assisted Lithology Prediction Solution?
Seven core technology components power this solution, each addressing a specific failure mode of manual or legacy automated interpretation.
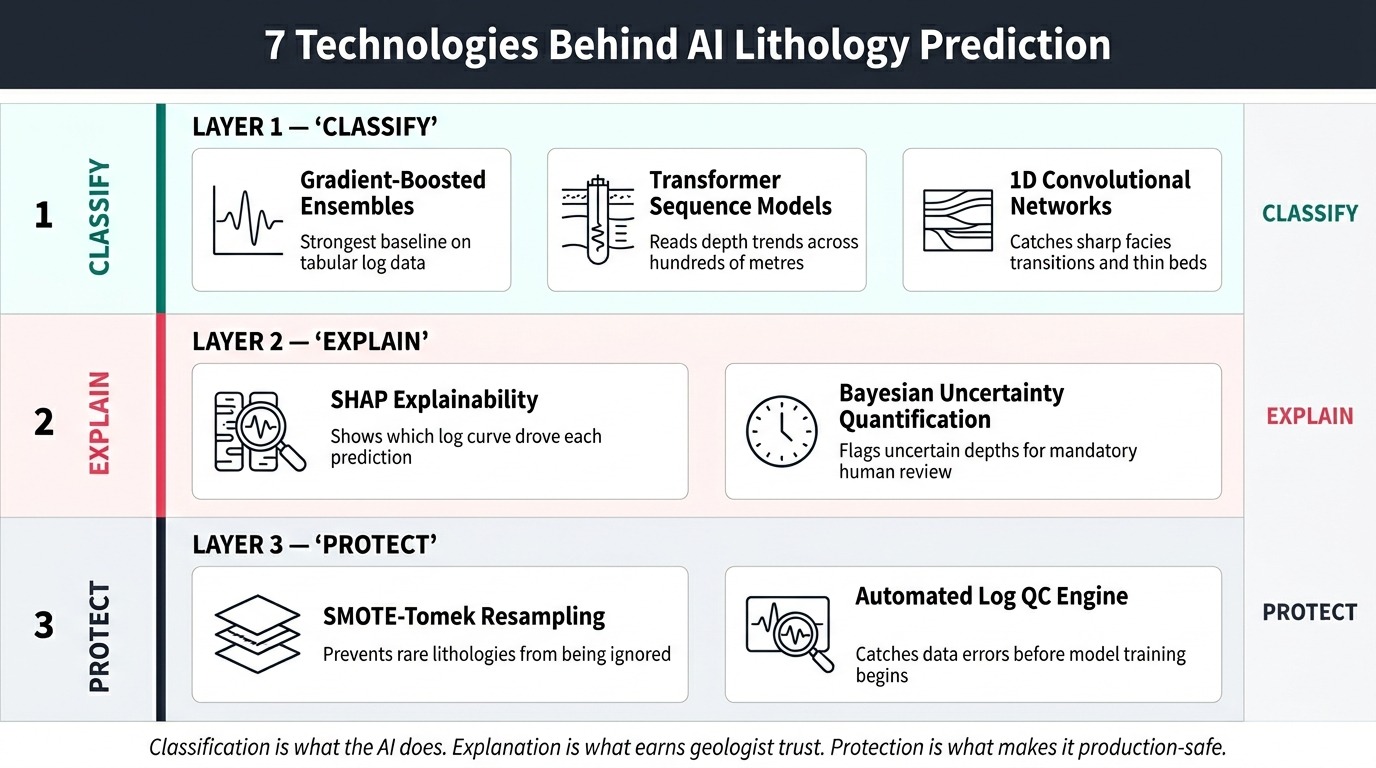
- Gradient-Boosted Ensemble ModelsMachine learning algorithms including Random Forest, XGBoost, and LightGBM that combine many decision trees to produce robust tabular predictions – consistently strong performers on well log classification benchmarks: These achieve the strongest baseline accuracy on well log classification tasks in published benchmarks. They handle missing curves naturally, produce calibrated probability outputs, and train efficiently on the 50 to 100+ well datasets required for basin-scale models – without requiring expensive compute infrastructure.
- Transformer-Based Sequence Models: Transformer architectures read log sequences across hundreds of metres of depth, capturing long-range stratigraphic trends that per-sample classifiers miss entirely. Attention masking enables the model to process incomplete log suites from legacy wells – accepting whatever curves are available and flagging uncertainty where key curves are absent, rather than failing or imputing false data.
- 1D Convolutional Neural Networks: CNNs detect sharp local anomalies in log traces – pay zone boundaries, thin beds, and facies transitions – that sequence models can smooth over. Combining CNNs with transformer layers in a hybrid architecture captures both local and long-range information simultaneously, improving accuracy on the complex intervals that matter most to drilling and completion decisions.
- SHAP Explainability Framework: SHAP computes how much each input log curve contributed to a specific depth-point prediction. It turns an opaque model output into a readable reasoning chain – which log curves drove the call, and by how much. Senior geologists can examine it, contest it, and sign off on it with a documented evidence trail. This is not optional: without it, experienced interpreters will not trust the output, and they are right not to.
- SMOTE-Tomek Hybrid Resampling: Rare lithologies – carbonates, evaporites, tight sand stringers – appear far less often in training data than shales. Without correction, the model learns to predict shale for anything it is uncertain about. SMOTE-Tomek fixes this by generating synthetic examples of rare classes and then cleaning out the noisy borderline samples that plain SMOTE leaves behind. The cleanup step matters: plain SMOTE alone can hurt performance on high-dimensional log data.
- Bayesian Uncertainty Quantification: Instead of outputting a single rock-type label at each depth, Bayesian methods produce a probability distribution across all candidate lithologies. This lets the system flag the depths where it is genuinely unsure – so geologist review time goes to the intervals that actually need it, not the straightforward ones.
- Automated Log Quality Control Engine: Before any machine learning runs, rule-based algorithms detect density spikes, sonic cycle-skipping, resistivity saturation, and washout-zone artefacts flagged by caliper readings. This step frequently surfaces data problems missed in manual review – and prevents the model from training on corrupted inputs that produce systematic prediction errors in specific depth zones.
6. What Results Does an AI Assisted Lithology Prediction Solution Deliver?
An AI Assisted Lithology Prediction Solution reduces per-well interpretation time for first-pass classification, compressing days of specialist work into hours of structured review. At the same time, it improves consistency across multi-well datasets. These two outcomes are structurally impossible to achieve together with manual approaches: faster means fewer eyes per well, more rigorous means slower throughput.
- Dramatically reduces per-well interpretation time: First-pass lithology classification drops from a full specialist workflow to a structured review of AI-generated outputs, enabling multi-well field programs to complete in weeks rather than quarters. The time saving compounds as portfolio size increases – the system processes additional wells without proportional additional specialist hours.
- Eliminates inconsistency across large well datasets: Every well in a field goes through the same normalisation, feature engineering, and classification logic. Formation top picks and sand/shale ratios become directly comparable across the full archive – often for the first time.
- Surfaces data quality problems that manual review misses at scale: Automated QC flags washout zones, spike artefacts, and systematic curve-generation errors across hundreds of wells simultaneously – identifying issues that only appear during multi-well cross-checks, not during single-well review.
- Redirects specialist attention to where it creates value: Rather than distributing petrophysicist effort uniformly across all depth intervals, the well log interpretation tool directs it precisely to flagged uncertainty zones. Geologists work harder only on the depths that genuinely need them.
- Enables near-real-time lithology support during drilling: In geosteering operations, the window between formation change and corrective decision shrinks from hours to minutes, reducing the risk of reservoir exit and the cost of well sidetracks.
- Scales to basin-wide programs without proportional headcount growth: The geological AI prediction tool processes additional wells without additional specialist time per well – allowing the same team to support a larger program or to deliver faster turnaround on existing workloads.
- Creates a defensible interpretation audit trail: SHAP contribution weights and confidence scores document the reasoning behind every classification, reducing the risk of challenged interpretations in reserves certification, joint venture reporting, or regulatory submissions.
- Reduces downstream completion and development errors: Improved first-pass accuracy on pay zone identification reduces the frequency of missed perforations, incorrect fracture stage placement, and well re-entries attributable to formation misidentification in the original interpretation.
7. Is an AI Assisted Lithology Prediction Solution Worth the Investment?
For any E&P operator running multi-well field programs, an AI Assisted Lithology Prediction Solution typically delivers positive ROI within the first large-scale reinterpretation project – and the case strengthens substantially as the platform extends to real-time drilling support.
In practice, organisations build the business case around a reinterpretation project first – because the before/after comparison on a 200-well legacy field is visible and quantifiable. Once output quality has been validated, the platform then expands to real-time drilling support. The metrics below provide the framework for building that internal business case.
Key Metrics to Measure Before and After Implementation
- Petrophysicist time per well: Baseline the current average hours spent on a full lithology evaluation before implementation – this varies significantly by well complexity, data quality, and team workflow, and should be measured directly from the organisation’s own logs rather than estimated from industry averages. Published ML lithology workflows consistently report substantial time compression for first-pass classification, though specific reduction percentages depend heavily on starting conditions. For a geoscience team running 300 wells annually, even a moderate reduction in per-well interpretation time represents meaningful capacity freed for higher-value work.
- Cost per well interpretation: Calculate the fully loaded cost including internal staff time and consulting petrophysicist engagements for peak demand. An AI lithology prediction AI platform shifts the cost structure from variable per-well consulting spend to a fixed development investment with significantly lower cost per well at scale.
- Time-to-decision for drilling programs: Measure the elapsed time from log data availability to approved lithology interpretation for individual wells and field-wide programs. Reductions here directly affect drilling schedule adherence and the carrying cost of wells waiting for formation evaluation sign-off.
- Interpretation consistency score: Run a blind multi-interpreter consistency test on a representative well set before and after implementation. Quantify the inter-interpreter variability in sand/shale ratio, net pay thickness, and formation top picks. A measurable reduction in this variance is a defensible quality metric for reserves reporting purposes.
- Error rate on pay zone identification: Track the frequency of formation re-perforations, missed pay zones, and well re-entries attributable to incorrect initial lithology calls. Each missed pay zone in a productive reservoir represents directly quantifiable unrealised production revenue over the well’s life.
A realistic implementation and payback timeline for a mid-size E&P operator with a 200 to 500 well portfolio: model development and basin calibration is typically measured in months, not weeks, with the data preparation phase almost always taking longer than the model development itself. Payback on that first reinterpretation project – measured against the consulting and internal time cost of the equivalent manual workflow – depends on portfolio scale, data quality, and internal sign-off cycles, and should be modelled against the organisation’s own cost structure rather than assumed from generic benchmarks. Published case studies are not yet available at scale for lithology-specific AI deployments; conservative project planning should treat the timeline as an estimate to validate against early pilot results.
The business case for acting now rather than waiting rests on data accumulation: every well drilled without AI-assisted interpretation adds to a reinterpretation backlog that grows more expensive to address as portfolio size increases.
8. What Does Deploying an AI Assisted Lithology Prediction Solution Actually Require?
Deploying an AI Assisted Lithology Prediction Solution requires labeled training data, a data quality investment, and a clear geologist validation workflow – not primarily a large IT infrastructure.
Here is what implementation experience consistently reveals that theoretical explanations miss: securing core-calibrated lithology descriptions from a geographically representative well set routinely takes longer than building the model. No algorithmic sophistication compensates for a training set that is too small or geologically unrepresentative. Recognising this early determines how the project gets scoped and staffed.
On accuracy expectations: the FORCE 2020 benchmark – 329 teams, 148 blind-test submissions, 12 lithofacies classes from offshore Norway – confirmed the best achievable accuracy on truly blind wells at approximately 80 percent. The competition’s geological analysis noted this ceiling likely reflects genuine label ambiguity in the training data itself, not just model limitations. That context matters when evaluating AI lithology prediction software claims in vendor literature: 80 percent on a rigorous blind test is a strong, practically useful result – not a shortcoming.
- Labeled training data availability: The system requires wells with core-calibrated lithology descriptions to serve as ground-truth training labels. The practical minimum for a formation-specific model varies by geological complexity and the number of distinct lithofacies present – a simple two-class sand-shale model can be trained on fewer wells than a 12-class system like the FORCE 2020 benchmark. Robust basin-scale models require substantially more: the FORCE 2020 competition used 98 training wells for a 12-class offshore Norway model as its reference dataset. Where core data is scarce, active learning workflows can extend labeled coverage incrementally – but there is no substitute for a representative baseline of ground-truth labels from the target formation.
- Data quality and format consolidation: LAS files from different operators, vintages, and tool generations require normalisation, unit standardisation, and quality checking before any training begins. Projects with extensive legacy data from the 1970s and 1980s face the most significant preprocessing burden – non-standard units, digitisation errors, and inconsistent curve naming across operators all require systematic resolution.
- Basin specificity and transfer learning limits: Models trained in one geological setting do not transfer reliably to a different basin without recalibration. Each new basin entry requires a set of local calibration wells with verified lithology. This is a real and frequently underestimated constraint – AI formation evaluation software is not basin-agnostic out of the box, and every deployment plan should account for the calibration investment required.
- Geologist validation workflow: A clear review and approval process – covering blind-well testing, core-to-model comparison, and sign-off procedures – must be defined before deployment, not during it. The AI output is a first-pass tool, and the validation workflow is what makes it production-ready for use in reserves reporting or development decisions.
- Integration with existing petrophysical software: The output lithology track must import cleanly into the petrophysical workstation and geological modelling environment already in use. Format compatibility testing and workflow integration work should begin early in the project, not as a final deployment step.
- Model maintenance and data drift: As a field is developed and new wells penetrate different parts of the formation, prediction accuracy can degrade if the model is not periodically retrained. Data driftThe gradual degradation of model accuracy that occurs when production data increasingly differs from training data – common in lithology models as wells penetrate new geological areas of a basin is a documented production risk, and a maintenance protocol for retraining triggers and frequency should be part of every deployment plan from day one.
- Team readiness and geologist buy-in: Senior geologists who have spent careers on manual interpretation require transparent, explainable outputs before they will trust any AI petrophysical analysis software system with formation evaluation decisions. SHAP explainability is not optional in this context – it is the technical mechanism through which geologist confidence gets built and sustained across the full organisation.
Where This Solution Has Real Limits
- Basin transfer accuracy drops significantly without recalibration: The FORCE 2020 lithology prediction benchmark showed the best blind-test accuracy reaching 80 percent within the training basin. Applied cross-basin without recalibration, accuracy degrades substantially – documented failure modes include geological formation mislabelling and systematic bias on minority lithologies. Published benchmark figures almost always reflect within-distribution performance, not generalisation to unfamiliar geology.
- Real-time drilling classification is noisier than post-drill wireline: Logging-while-drilling data carries mechanical vibration, telemetry dropouts, and formation fluid invasion effects that post-drill wireline logs do not. Near-real-time performance is practically achievable, but confidence scores on LWD-derived classifications are lower than on a complete post-drill log suite. Expect higher uncertainty flag rates in real-time deployments and design the review workflow around that.
- Thin beds and rare lithologies remain challenging: Carbonate stringers, evaporite layers, and tight sand intervals are structurally underrepresented in training data regardless of resampling technique. The system flags these as uncertain rather than misclassifying them confidently, but thin-bed analysis always requires human review.
- The core data bottleneck cannot be engineered away: In frontier basins with no previous drilling history, the system cannot operate without a minimum baseline of core-calibrated training wells. No amount of synthetic data generation or transfer learning fully replaces physical core descriptions from the target formation for initial basin calibration.
9. Who Benefits Most from an AI Assisted Lithology Prediction Solution?
An AI Assisted Lithology Prediction Solution delivers the highest value to E&P operators, geoscience service firms, and national oil companies managing portfolios of 50 or more wells – particularly those facing multi-well programs, legacy data backlogs, or rapid basin-entry evaluations.
E&P companies running active field development or redevelopment programs get the most value – especially those with large legacy well archives, multi-well drilling campaigns, or basin-entry evaluations that need rapid formation characterisation. Geoscience consulting firms that deliver petrophysical services across multiple clients gain leverage through a consistent, scalable methodology rather than individual-interpreter workflows. National oil companies with extensive historical archives and limited specialist capacity find it particularly useful for modernising legacy field interpretations at scale without growing headcount.
This solution is particularly valuable if:
- The organisation manages more than 50 wells requiring consistent petrophysical interpretation, and current manual throughput cannot keep pace with field development timelines
- The drilling program includes directional wells requiring near-real-time lithology support for geosteering operations where post-drill interpretation is too slow to influence decisions
- Reinterpretation of legacy well data is the primary business case for a new field development, production optimisation program, or reserves upgrade exercise
- The geoscience team operates across multiple concurrent projects with insufficient petrophysicist capacity to deliver full manual interpretation workflows on all fronts simultaneously
- Data consistency across multiple operators, vintages, or field partitions is a requirement for reserves certification, joint venture reporting, or regulatory submission
Oil field service companies delivering formation evaluation as part of drilling contracts also represent a strong fit profile. Deploying a lithology prediction AI platform allows these organisations to serve more clients with the same specialist capacity, deliver more consistent quality across engagements, and differentiate their service offering with faster turnaround and fully auditable interpretation records.
10. Frequently Asked Questions About AI Lithology Prediction
How accurate is AI assisted lithology prediction for oil and gas wells in practice?
Accuracy depends heavily on how geologically similar the test wells are to the training data. The FORCE 2020 competition – the most rigorous published benchmark, using 98 training wells and 10 truly blind test wells from offshore Norway – showed the best model reaching 80 percent accuracy on blind data, with runner-up models at 78 to 79 percent across 12 lithofacies classes. The competition organisers noted that the 80 percent ceiling likely reflects genuine label uncertainty in the training data itself, not just model limitations. Applied cross-basin without recalibration, performance degrades substantially. The AI Assisted Lithology Prediction Solution is designed for within-basin, first-pass classification and should be evaluated against that benchmark – not against cross-basin generalisation claims that don’t reflect realistic deployment conditions.
Can an automated well log interpretation platform handle legacy wells with missing or incomplete log curves?
Modern architectures using attention masking can process incomplete log suites by weighting only the curves that actually exist in a given well, rather than requiring a full standard suite. This capability is critical for legacy wells from the 1970s and 1980s that frequently lack neutron-density pairs or photoelectric factor measurements. However, predictions for wells missing key discriminating curves will carry higher uncertainty flags, and the confidence scores reflect the data limitation honestly. The system flags where data gaps create genuine interpretive ambiguity rather than producing false confidence on incomplete inputs.
What data does an AI formation evaluation tool need to work accurately in a new basin?
The practical data requirement depends on the number of distinct lithofacies being classified and the geological complexity of the target basin. A two-class sand-shale model can be trained on fewer labeled wells than a 12-class system. For context, the FORCE 2020 benchmark used 98 training wells to build a 12-class model for offshore Norway – the most rigorous published reference for what basin-scale classification requires. Well logs themselves are rarely the limiting factor. The bottleneck is almost always the availability of core data providing verified ground-truth labels. Basin calibration investment is a real project cost that should be scoped explicitly from the start.
How does an AI subsurface analysis platform for drilling teams help with real-time geosteering?
During an active drilling operation, the platform processes logging-while-drilling and drilling parameter data as it arrives from the downhole tool, classifying each new depth increment into a lithology category with a confidence score. When the log signature shifts – indicating a formation change – the system flags the wellsite geologist with an alert and an updated prediction before the bit has drilled significantly past the boundary. This reduces the window between formation change and corrective geosteering action from hours to minutes. The wellsite geologist retains full decision authority; the AI functions as a first-pass interpreter working continuously without fatigue or attention lapses.
How long does it take to implement an AI well log interpretation solution for E&P companies?
Implementation timeline is primarily determined by data preparation and geologist sign-off cycles, not model development. A formation-specific model on a single well-documented field moves faster than a basin-scale model covering multiple fields and operators. In either case, the data consolidation and quality review phase – not algorithm development – is almost always the longest stage. Projects that scope the data preparation work explicitly from the start, and establish clear validation criteria before training begins, consistently reach production deployment faster than those that treat data preparation as a secondary concern. No standardised benchmarks for lithology AI deployment timelines have been published across multiple case studies; treating any quoted timeline as an estimate to validate against a pilot is the appropriate approach.
Build This Solution With Softlabs Group
Softlabs Group builds custom AI lithology prediction systems tailored to the specific formation types, log suites, and petrophysical workflows of each client’s basin and operational context. This is not a preconfigured software installation – it is an end-to-end engineering engagement covering data ingestion pipeline design, model training and basin calibration, explainability layer integration, and deployment into the client’s existing geoscience environment. Our team works with a domain expert geologist in the loop at every stage of development, not just at sign-off. For enterprise AI development engagements requiring integration with subsurface data management platforms and geological modelling environments, we cover the full system integration scope from data pipeline to production deployment.
Whether the immediate need is a large-scale legacy field reinterpretation, a real-time geosteering decision support tool, or a basin-entry formation characterisation system, the engagement begins with understanding your specific well data, target formations, and the decision workflows the interpretation must feed. Reach out to discuss your basin context and data situation – no commitment required at that stage.